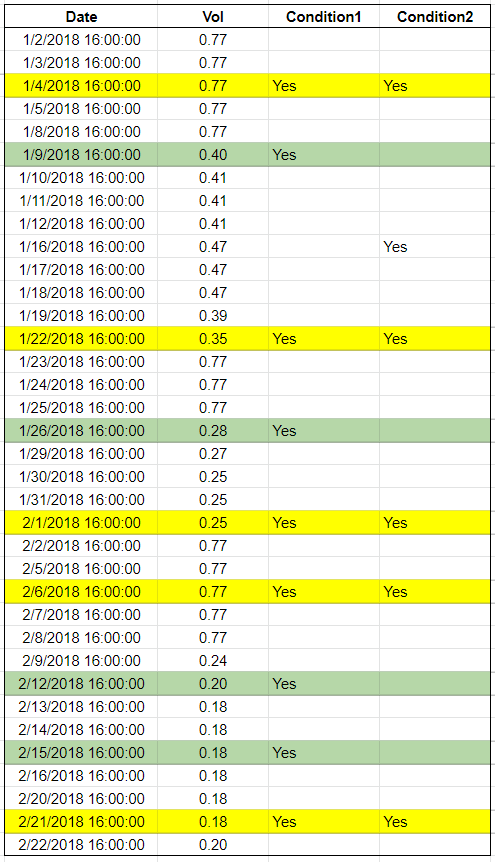
I have dataframe df as shown in the first photo. Green rows are the ones which have column Condition1 as 'Yes'. Yellow rows are the ones which have BOTH columns Condition1 and Condition2 as 'Yes'.
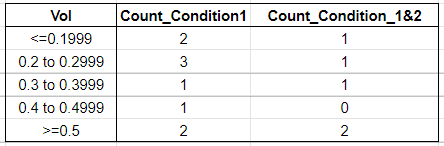
Question: See second photo which shows desired output which is a new dataframe in which:
(1). Column 'Count_Condition1' contains the number of times green row occurs. The column 'Count_Condition_1&2' contains the number of times yellow rows occur.
(2). In addition to (1), I would like to split the column 'Vol' to different ranges (see second photo) and the counts be displayed accordingly.
For example, there are 3 instances when Condition1= 'Yes' and the data range for Vol is between 0.2 to 0.2999.
CodePudding user response:
Use cut for bining column Vol and for count match Yes values create helper columns, last aggregate boolean for count Trues:
bins=[-np.inf, 0.2, 0.3, 0.4, 0.5, np.inf]
labels = [ f'{a} to {round(b-0.0001, 4)}'.replace('-inf to ', '<=').replace(' to inf', '')
for a, b in zip(bins, bins[1:])]
labels[-1] = '>=' labels[-1]
s1 = df['Condition1'].eq('Yes')
s2 = df['Condition2'].eq('Yes')
g = pd.cut(df['Vol'], bins = bins, right = False, labels = labels)
df1 = (df.assign(Count_Condition1 = s1, Count_Condition_1_2 = s1 & s2)
.groupby(g)[['Count_Condition1','Count_Condition_1_2']]
.sum())
print (df1)
Count_Condition1 Count_Condition_1_2
Vol
<=0.1999 2 1
0.2 to 0.2999 3 1
0.3 to 0.3999 1 1
0.4 to 0.4999 1 0
>=0.5 2 2