I have a dataframe
df = pd.DataFrame({'≤8': {1: '3687 55.5', 2: '838 66.5', 3: '8905 66.9'},
'9–13': {1: '2234 33.6', 2: '419 33.3', 3: '3362 25.2'},
'14–15': {1: '290 4.4', 2: nan, 3: '473 3.6'},
'16–17': {1: '194 2.9', 2: nan, 3: '252 1.9'},
'18–20': {1: '185 2.8', 2: nan, 3: '184 1.4'},
'≥21': {1: '52 0.8', 2: '0 0.0', 3: '144 1.1'}})
≤8 9–13 14–15 16–17 18–20 ≥21
1 3687 55.5 2234 33.6 290 4.4 194 2.9 185 2.8 52 0.8
2 838 66.5 419 33.3 NaN NaN NaN 0 0.0
3 8905 66.9 3362 25.2 473 3.6 252 1.9 184 1.4 144 1.1
I want to split all the columns into two columns, so there is an int columns and a float column (note, I don't care to separate by type, the types are just coincidental). I got as far as splitting the columns, but I can't figure out how to assign the resulting lists into new columns. I also want to keep it as pythonic/pandonic as possible, so I don't want to loop over each column individually.
rev = gestation_cols.apply(lambda x: pd.Series([i for i in x.str.split(' ')]))
≤8 9–13 14–15 16–17 18–20 ≥21
0 [3687, 55.5] [2234, 33.6] [290, 4.4] [194, 2.9] [185, 2.8] [52, 0.8]
1 [838, 66.5] [419, 33.3] NaN NaN NaN [0, 0.0]
2 [8905, 66.9] [3362, 25.2] [473, 3.6] [252, 1.9] [184, 1.4] [144, 1.1]
3 [1559, 48.6] [1075, 33.5] [209, 6.5] [165, 5.1] [173, 5.4] [26, 0.8]
edit: For clarity, I do not want to split a single column or split each column individually. I know I could create new columns one by one, that's simply bad practice. I want each and every of the columns to be split into two columns.
CodePudding user response:
For a vectorial version you can temporarily 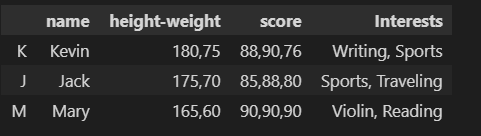
Split with "str.split" method:
df["height-weight"].str.split(",")
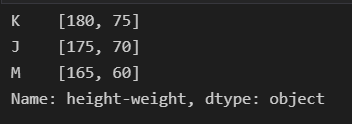
You will find the split result (list) is a Series (one column contains list value), yet different from our expected result.
So let’s add another option in split() method to achieve this goal. This option is expand, if we specified expand=True, two columns will be generated.
df["height-weight"].str.split(",", expand=True)

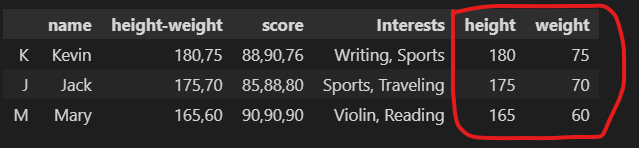
If we use two columns to accept this result, we can add height and weight column to df DataFrame.
df[["height", "weight"]] = df["height-weight"].str.split(",", expand=True)
df
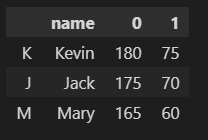
If you want to concatenate new columns by splitting and some columns of original DataFrame to a new DataFrame, you can use concat() method of Pandas. concat() accepts a list of DataFrame, axis=1 means concatenate DataFrames in horizontal direction. Note: The new columns by splitting have no column names but 0,1.
df2 = pd.concat([df["name"], df["height-weight"].str.split(",",
expand=True)], axis=1)
df2
CodePudding user response:
It should be faster if you iterate through it (you are iterating through the columns, which is ok compared to row looping):
pd.concat({key : value.str.split(expand = True)
for key, value in df.items()},
axis = 1)
≤8 9–13 14–15 16–17 18–20 ≥21
0 1 0 1 0 1 0 1 0 1 0 1
1 3687 55.5 2234 33.6 290 4.4 194 2.9 185 2.8 52 0.8
2 838 66.5 419 33.3 NaN NaN NaN NaN NaN NaN 0 0.0
3 8905 66.9 3362 25.2 473 3.6 252 1.9 184 1.4 144 1.1
Of course, only tests can tell - it feels a bit more expensive to flip to long (stack), then back to wide (unstack) - when you can run the process within the wide form.