I have the following raw data export:
import pandas as pd
df = pd.DataFrame({
'Data': ['A15','abc','A25',50,'abc','A30',20,'def','A4','hijk','A',10,'mnop'],
})
df

I am trying to transpose this raw data to a table with 3 columns: Name, Number and Text
I would like a row for every time A appears as this is the consistent pattern. After that there is always a text but only sometimes there is a number. If this number appears it is always the direct row after the A. My expected output is this:
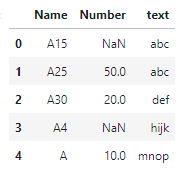
Any ideas on how i can approach this? Thanks very much!
CodePudding user response:
You can define masks and use a pivot:
m1 = df['Data'].str.startswith('A')
m2 = m1.isna() #OR: pd.to_numeric(df['Data'], errors='coerce').notna()
m1 = m1.fillna(False)
df2 = (df
.assign(index=m1.cumsum(),
col=np.select([m1, m2], ['Name', 'Number'], 'Text')
)
.pivot(index='index', columns='col', values='Data')
)
output:
col Name Number Text
index
1 A15 NaN abc
2 A25 50 abc
3 A30 20 def
4 A4 NaN hijk
5 A 10 mnop
intermediates:
Data m1 m1(v2) m2 m1(cumsum)
0 A15 True True False 1
1 abc False False False 1
2 A25 True True False 2
3 50 NaN False True 2
4 abc False False False 2
5 A30 True True False 3
6 20 NaN False True 3
7 def False False False 3
8 A4 True True False 4
9 hijk False False False 4
10 A True True False 5
11 10 NaN False True 5
12 mnop False False False 5
CodePudding user response:
import re
import pandas as pd
import numpy as np
df = pd.DataFrame({'Data': ['A15', 'abc', 'A25', 50, 'abc', 'A30', 20, 'def', 'A4', 'hijk', 'A', 10, 'mnop']})
convert to list:
flat_list = df['Data'].tolist()
iterate over list, if element matches A\d add new sublist otherwise append to last sublist:
nested_list = []
while len(flat_list) > 0:
element = flat_list.pop(0)
if re.fullmatch("A\d*", str(element)):
nested_list.append([element])
else:
nested_list[-1].append(element)
to list of dicts where 'Number' is np.NaN if a sublist has only two items:
as_records = [
{'Name': l[0], 'Number': l[1], 'text': l[2]} if len(l) == 3 else {'Name': l[0], 'Number': np.NaN, 'text': l[1]}
for l in nested_list]
convert to DataFrame:
df_out = pd.DataFrame(as_records)
Which returns:
Name Number text
0 A15 NaN abc
1 A25 50.0 abc
2 A30 20.0 def
3 A4 NaN hijk
4 A 10.0 mnop