import requests
from bs4 import BeautifulSoup
import csv
from itertools import zip_longest
job_title = []
company_name = []
location_name = []
job_skill = []
links = []
salary = []
result = requests.get("https://wuzzuf.net/search/jobs/?q=python\&a=hpb")
source = result.content
soup = BeautifulSoup(source, "lxml")
job_titles = soup.find_all("h2", {"class": "css-m604qf"})
company_names = soup.find_all("a", {"class": "css-17s97q8"})
location_names = soup.find_all("span", {"class": "css-5wys0k"})
job_skills = soup.find_all("div", {"class": "css-y4udm8"})
for i in range(len(job_titles)):
job_title.append(job_titles[i].text)
links.append("https://wuzzuf.net" job_titles[i].find("a").attrs["href"])
company_name.append(company_names[i].text)
location_name.append(location_names[i].text)
job_skill.append(job_skills[i].text)
for link in links:
result = requests.get(link)
source = result.content
soup = BeautifulSoup(source, "lxml")
salaries = soup.find("span", {"class": "css-4xky9y"})
salary.append(salaries)
file_list = [job_title, company_name, location_name, job_skill, links, salary]
exported = zip_longest(*file_list)
with open("/Users/Rich/Desktop/JobTutorial.csv", "w") as myfile:
writer = csv.writer(myfile)
writer.writerow(["Job titles", "Company names", "Location names", "Job skills", "Links", "Salary"])
writer.writerows(exported)
print(salary)
the problem is that salaries function returns nothing, when i appended its results to a list named salary and printed out the results, it printed a list of Nones...
[None, None, None, None, None, None, None, None, None, None, None, None, None, None, None]
please help me guys and i appreciate your help.
CodePudding user response:
The salary data is dynamically generated, if you check the source code/Page source (ctrl U on chrome) of the job post you can see that the data is not in the HTML element. But it can be found under <script> tag inside Wuzzuf.initialStoreState object
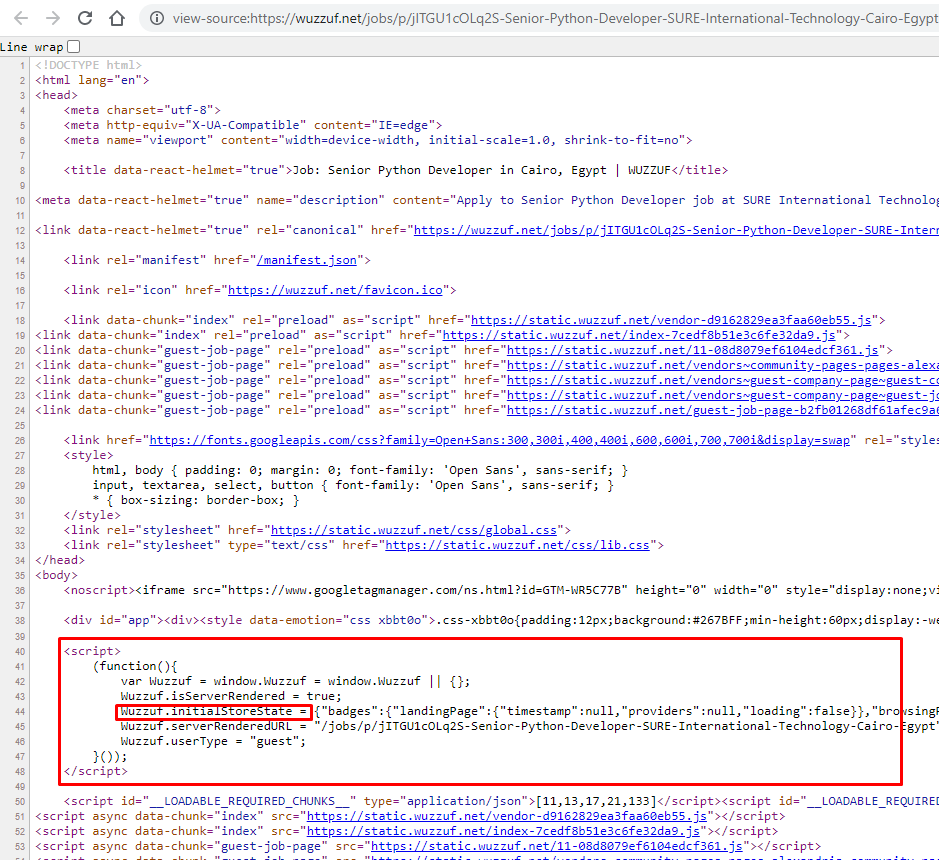
Now you have to parse this json file to get the job details data. you can do that using regex
Here is a working code to parse the dictionary for a single job from that list -
link = "https://wuzzuf.net/jobs/p/jITGU1cOLq2S-Senior-Python-Developer-SURE-International-Technology-Cairo-Egypt"
result = requests.get(link, headers=headers)
raw_data = re.compile(r'Wuzzuf.initialStoreState = (.*);').search(result.text)
job_details_dict = json.loads(raw_data.group(1).strip())
job_details_dict
sample Output -
{'badges': {'landingPage': {'loading': False,
'providers': None,
'timestamp': None}},
'browsingPage': {'sets': {}},
'coaches': {'coachesContactUs': {}, 'coachesPartner': {}},
.................
Now you just need to parse your desired data (e.g., salary) from this dictionary