I have big dataset of values as follow:
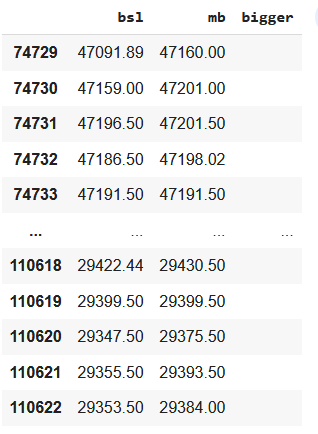
column "bigger" would be index of the first row with bigger "bsl" than "mb" from current row. I need to do it without loop as I need it to be done in less than a second. by loop it's over a minute.
For example for the first row (with index 74729) the bigger is going to be 74731. I know it can be done by linq in C# but I'm almost new in python.
here is another example:
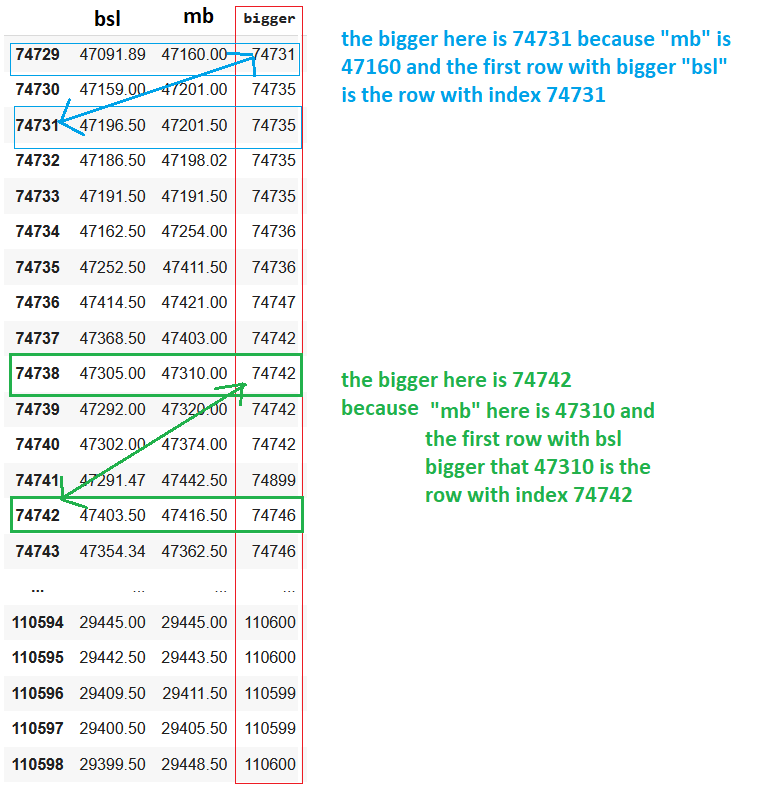
here is text version:
index bsl mb bigger
74729 47091.89 47160.00 74731.0
74730 47159.00 47201.00 74735.0
74731 47196.50 47201.50 74735.0
74732 47186.50 47198.02 74735.0
74733 47191.50 47191.50 74735.0
74734 47162.50 47254.00 74736.0
74735 47252.50 47411.50 74736.0
74736 47414.50 47421.00 74747.0
74737 47368.50 47403.00 74742.0
74738 47305.00 47310.00 74742.0
74739 47292.00 47320.00 74742.0
74740 47302.00 47374.00 74742.0
74741 47291.47 47442.50 74899.0
74742 47403.50 47416.50 74746.0
74743 47354.34 47362.50 74746.0
CodePudding user response:
I'm not sure how many rows you have, but if the number is reasonable, you can perform a pairwise comparison:
# get data as arrays
a = df['bsl'].to_numpy()
b = df['mb'].to_numpy()
idx = df.index.to_numpy()
# compare values and mask lower triangle
# to ensure comparing only the greater indices
out = np.triu(a>b[:,None]).argmax(1).astype(float)
# reindex to original indices
idx = idx[out]
# mask invalid indices
idx[out<np.arange(len(out))] = np.nan
df['bigger'] = idx
Output:
bsl mb bigger
0 1 2 2.0
1 2 4 6.0
2 3 3 5.0
3 2 1 3.0
4 3 5 NaN
5 4 2 5.0
6 5 1 6.0
7 1 0 7.0
CodePudding user response:
Not sure if this is what you're looking for, but this is without loops:
import pandas as pd
import numpy as np
df = pd.DataFrame(df)
indDF = df[df['bsl']>df['mb']]
ind = np.arra(indDF.index)
z = np.array([0])
ind1 = np.append(z,ind[:-1])
diff = np.ediff1d(ind1)
last = len(df)- np.sum(diff)
diff = np.append(diff,last)
rep = np.repeat(ind,diff)
df['bigger'] = rep
Output1:
df = {"bsl": [1,1,1,2,2,2,2,3,5],
"mb" : [0,4,3,7,0,1,2,4,4]}
bsl mb bigger
0 1 0 4
1 1 4 4
2 1 3 4
3 2 7 4
4 2 0 5
5 2 1 8
6 2 2 8
7 3 4 8
8 5 4 8
Output2:
df = {"bsl": [1,2,3,2,3,4,5,1],
"mb" : [2,4,3,1,5,2,1,0]}
bsl mb bigger
0 1 2 3
1 2 4 3
2 3 3 3
3 2 1 5
4 3 5 5
5 4 2 6
6 5 1 7
7 1 0 7