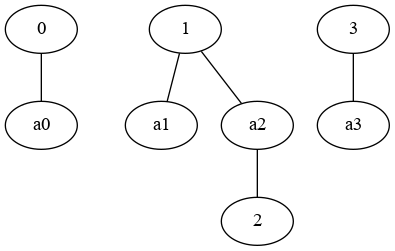
I have a table like:
col1 col2
0 1 a
1 2 b
2 2 c
3 3 c
4 4 d
I'd like rows to be grouped together if they have a matching value in col1 or col2. That is, I'd like something like this:
> (
df
.groupby(set('col1', 'col2')) # Made-up syntax
.ngroup())
0 0
1 1
2 1
3 1
4 2
Is there a way to do this with pandas?
CodePudding user response:
This is not easy to achieve simply with pandas. Indeed, two far away groups can become connected when two items are connected in the second group.
You can approach this using graph theory. Find the connected components using edges formed by the two (or more) groups. A python library for this is