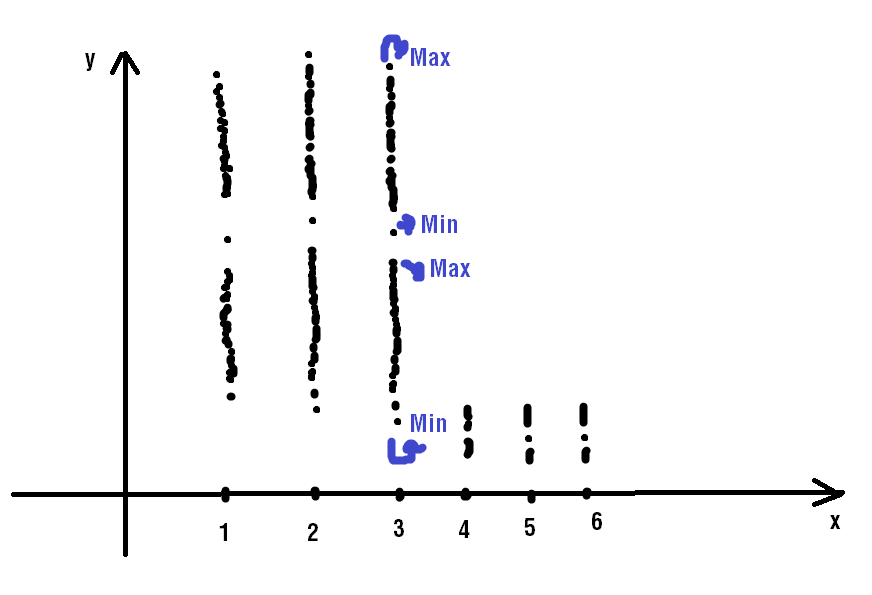
I have a text file that has a long 2D array. The first element of each has numbers between 1 to 6.
I want to cluster the lines. How can the minimum and maximum values of a cluster be determined for this data, here in the range from 0 to 6, taking into account that each element ranging from 1-6 has two clusters?
Looking at the blue cluster, I would like to determine the min and max values for each cluster as the boundaries of the cluster. Which algorithm can solve this problem? I would need to find min-max for all clusters of those 6 lines.
CodePudding user response:
You should be using kmeans for clustering and some dictionary mapping for getting min/max value:
Code:
import numpy as np
import numpy as np
from scipy.cluster.vq import kmeans, vq
from collections import defaultdict
dd = defaultdict(list)
arr = [[1, 2], [3,585], [2, 0], [1, 500], [2, 668], [3, 54], [4, 28], [3, 28], [4,163], [3,85], [4,906], [2,5000], [2,358], [4,69], [3,89], [4, 258],[2, 632], [4, 585], [3, 47]]
for k in arr:
dd[k[0]].append(k[1]) #creating dictionary containing first element of arr as key and last element as value
dd = dict(dd)
Before trying to understand below code, first have a look at here
"""
This below code creates new dict based on the previous dict data
The dict keys have 2 lists as values, containing min/max value for each cluster
"""
new_dd = defaultdict(list)
for k, v in dd.items():
codebook, _ = kmeans(np.array(v, dtype=float), 2) # 2 clusters
cluster_indices, _ = vq(v, codebook) #creates indices of cluster for each element
#defining 2 clusters
zero_cluster= []
one_cluster = []
for i, val in enumerate(cluster_indices):
if val == 0:
zero_cluster.append(v[i])
else:
one_cluster.append(v[i])
min_zero=0
max_zero=0
min_one=0
max_one=0
if len(zero_cluster)>0:
min_zero = min(zero_cluster)
max_zero = max(zero_cluster)
if len(one_cluster)>0:
min_one = min(one_cluster)
max_one = max(one_cluster)
#adding stats to the new dict based on cluster
new_dd[k].append([[min_one, max_one],[min_zero, max_zero]])
new_dd = dict(new_dd)
new_dd = {k:v[0] for k,v in new_dd.items()}
print(new_dd)