I want to do a scan of a multilingual parallel corpus to evaluate possible equivalences. For that I need texplot_xray() to return multiple answers in a single column.
In the first search, where the word of Latin origin is used equally in English, Italian and Spanish, some degree of equivalence seems to be interpreted, which is not the case for French human => l'homme.
# require(quanteda)
# require(quanteda.corpora)
# require(quanteda.texplots)
corpusa <- data_corpus_udhr[c('ita', 'eng', 'eus', 'spa', 'fra')]
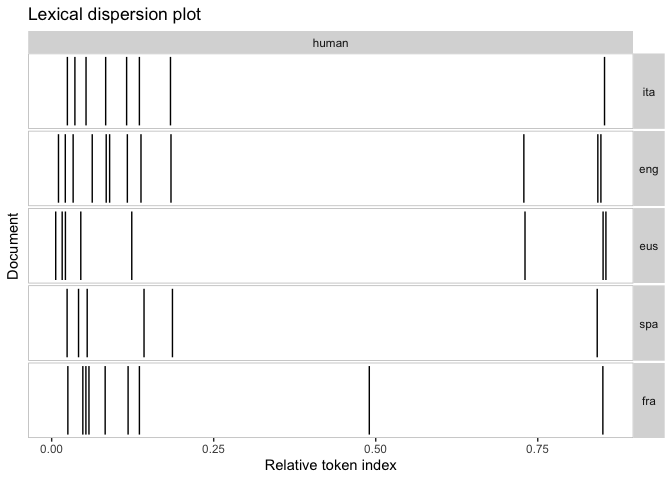
quanteda.textplots::textplot_xray(kwic(x = corpusa, pattern = '*uman*'))
Results of a search in four languages (five, one no result)
{kind=link}
When searching more closely, I would like to summarise the equivalents in the one relevant column.
bilaketa <- c('umani', 'human', 'giza', 'humanos', "l'homme")
quanteda.textplots::textplot_xray(kwic(corpusa, pattern = phrase(bilaketa)))
Results reducible to a single relevant column
{kind=link}
Is there a way to resolve such queries?
CodePudding user response:
You can use a dictionary as a pattern in the kwic(), although you will get the dictionary key as the column total rather than the individual (pattern) value, as in the case with the five columns.
library("quanteda")
## Package version: 3.2.1
## Unicode version: 14.0
## ICU version: 70.1
## Parallel computing: 8 of 8 threads used.
## See https://quanteda.io for tutorials and examples.
library("quanteda.textplots")
data(data_corpus_udhr, package = "quanteda.corpora")
corpusa <- data_corpus_udhr[c("ita", "eng", "eus", "spa", "fra")]
bilaketa <- c("umani", "human", "giza", "humanos", "l'homme")
corpusa %>%
tokens() %>%
kwic(pattern = dictionary(list(human = bilaketa))) %>%
textplot_xray()