I have a toy example as follows
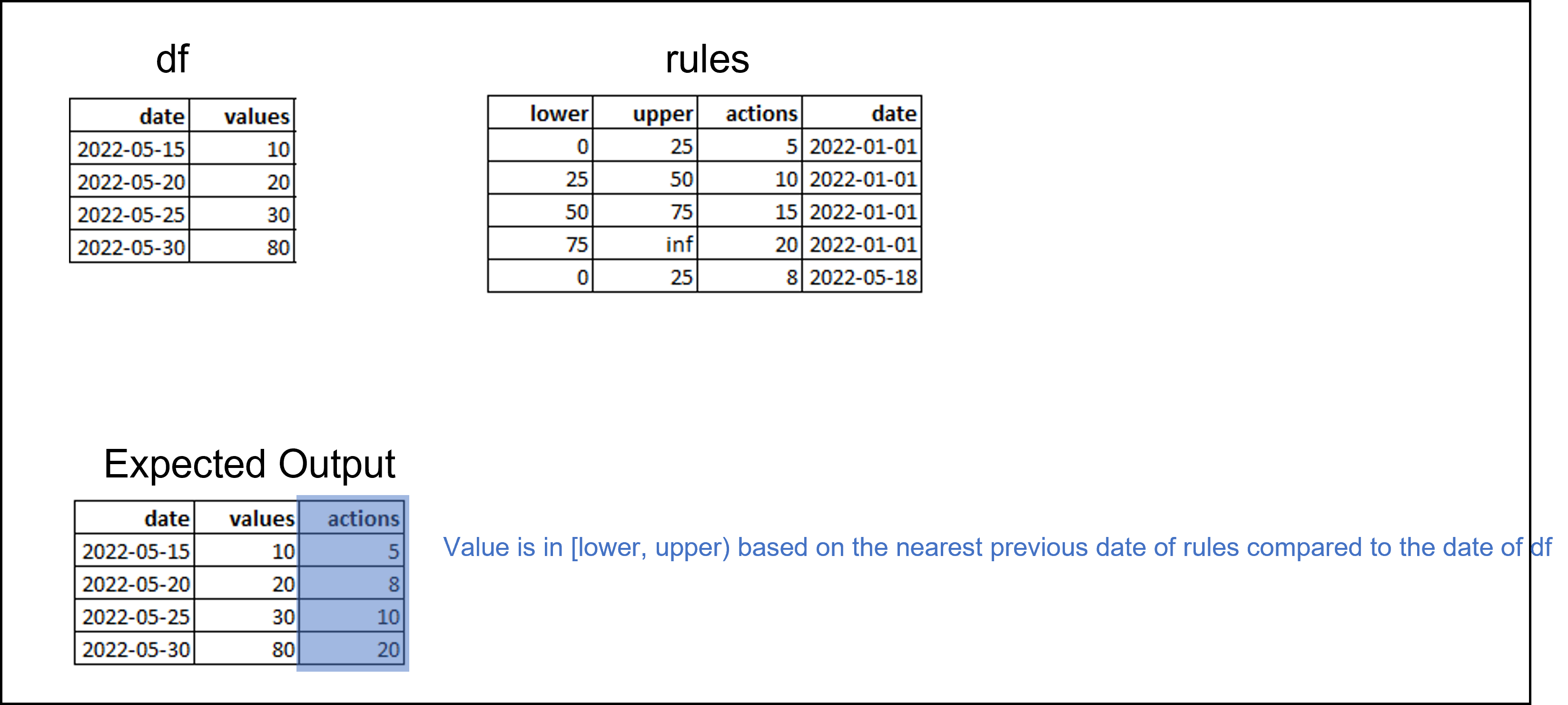
I would like to merge the actions column in rules to the original df. Merging conditions are the following.
- (value >= lower) & (value < upper)
- date in df must merge with the nearest previous date in rules
The expected output is shown in the above figure. Here is the df and rules
df = pd.DataFrame({"date": ["2022-05-15", "2022-05-20", "2022-05-25", "2022-05-30"],
"values": [10, 20, 30, 80]})
df["date"] = pd.to_datetime(df["date"])
rules = pd.DataFrame({"lower": [0, 25, 50, 75, 0],
"upper": [25, 50, 75, float("inf"), 25],
"actions": [5, 10, 15, 20, 8],
"date": ["2022-01-01", "2022-01-01", "2022-01-01", "2022-01-01", "2022-05-18"]})
rules["date"] = pd.to_datetime(rules["date"])
May I have suggestions about effective method to do this?
CodePudding user response:
One option is with conditional_join from pyjanitor, and after the merge, you can do a groupby to get the minimum rows:
# install from dev
# pip install git https://github.com/pyjanitor-devs/pyjanitor.git
import janitor
import pandas as pd
(df
.astype({'values':float})
.conditional_join(
rules.astype({'lower':float}),
# pass the conditions as a variable arguments of tuples
('values', 'lower', '>='),
('values', 'upper', '<'),
('date', 'date', '>'),
# select required columns with df_columns, and right_columns
df_columns = ['date','values'],
right_columns={'actions':'actions', 'date':'date_right'})
# get the difference and keep the smallest days
.assign(dff = lambda df: df.date.sub(df.date_right))
.sort_values(['date', 'dff'])
.drop(columns = ['dff', 'date_right'])
.groupby('date', sort = False, as_index = False)
.nth(0)
)
date values actions
0 2022-05-15 10.0 5
3 2022-05-20 20.0 8
4 2022-05-25 30.0 10
5 2022-05-30 80.0 20