I need to use some names of the columns as part of the df. While keeping the first 3 columns identical, I need to create some other columns based on the content of the row.
Here I have some transactions from some customers:
cust_id cust_first cust_last au_zo au_zo_pay fi_gu fi_gu_pay wa wa_pay
0 1000 Andrew Jones 50.85 debit NaN NaN 69.12 debit
1 1001 Fatima Lee NaN NaN 18.16 debit NaN NaN
2 1002 Sophia Lewis NaN NaN NaN NaN 159.54. credit
3 1003 Edward Bush 45.29 credit 59.63 credit NaN NaN
4 1004 Mark Nunez 20.87 credit 20.87 credit 86.18 debit
First, I need to add a new column, 'city'. Since it is not on the database. It is defaulted to be 'New York'. (that's easy!)
But here is where I am getting stuck:
Add a new column 'store' holds values according to where a transaction took place. au_zo --> autozone, fi_gu --> five guys, wa --> walmart
Add new column 'classification' according to the store previously added: auto zone --> auto-repair, five guys --> food, walmart --> groceries
Column 'amount' holds the value of the customer and store.
Column 'transaction_type' is the value of au_zo_pay, fi_gu_pay, wa_pay respectively.
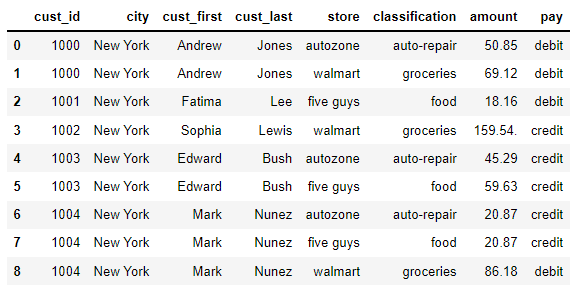
So at the end it looks like this:
cust_id city cust_first cust_last store classification amount trans_type
0 1000 New York Andrew Jones auto zone auto-repair 50.85 debit
1 1000 New York Andrew Jones walmart groceries 69.12 debit
2 1001 New York Fatima Lee five guys food 18.16 debit
3 1002 New York Sophia Solis walmart groceries 159.54 credit
4 1003 New York Edward Bush auto zone auto-repair 45.29 credit
5 1003 New York Edward Bush five guys food 59.63 credit
6 1004 New York Mark Nunez auto zone auto-repair 20.87 credit
7 1004 New York Mark Nunez five guys food 20.87 credit
8 1004 New York Mark Nunez walmart groceries 86.18 debit
I have tried using df.melt() but I don't get the results.
CodePudding user response:
Try this
# assign city column and set index by customer demographic columns
df1 = df.assign(city='New York').set_index(['cust_id', 'city', 'cust_first', 'cust_last'])
# fix column names by completing the abbrs
df1.columns = df1.columns.to_series().replace({'au_zo': 'autozone', 'fi_gu': 'five guys', 'wa': 'walmart'}, regex=True)
# split column names for a multiindex column
df1.columns = pd.MultiIndex.from_tuples([c.split('_') if c.endswith('pay') else [c, 'amount'] for c in df1.columns], names=['store',''])
# stack df1 to make the wide df to a long df
df1 = df1.stack(0).reset_index()
# insert classification column
df1.insert(5, 'classification', df1.store.map({'autozone': 'auto-repair', 'five guys': 'food', 'walmart': 'groceries'}))
df1
CodePudding user response:
Is this something you want?
import pandas as pd
mp = {
'au_zo': 'auto-repair',
'wa':'groceries',
'fi_gu':'food'
}
### Read txt Data: get pandas df
# I copied and pasted your sample data to a txt file, you can ignore this part
with open(r"C:\Users\orf-haoj\Desktop\test.txt", 'r') as file:
head, *df = [row.split() for row in file.readlines()]
df = [row[1:] for row in df]
df = pd.DataFrame(df, columns=head)
### Here we conduct 2 melts to form melt_1 & melt_2 data
# this melt table is to melt cols 'au_zo','fi_gu', and 'wa'. & get amount as value
melt_1 = df.melt(id_vars=['cust_id', 'cust_first', 'cust_last'], value_vars=['au_zo','fi_gu','wa'], var_name='store', value_name='amount')
# this melt table is to melt cols ['au_zo_pay','fi_gu_pay','wa_pay']. & get trans_type cols
melt_2 = df.melt(id_vars=['cust_id', 'cust_first', 'cust_last'], value_vars=['au_zo_pay', 'fi_gu_pay', 'wa_pay'], var_name='store pay', value_name='trans_type')
# since I want to join these table later, it will a good to get one more key store
melt_2['store'] = melt_2['store pay'].apply(lambda x: '_'.join(x.split("_")[:-1]))
### Remove NaN
# you prob want to switch to test = test.loc[~test['amount'].isnull()] or something else if you have actual nan
melt_1 = melt_1.loc[melt_1['amount'] != 'NaN']
melt_2 = melt_2.loc[melt_2['trans_type'] != 'NaN']
### Inner join data based on 4 keys (assuming your data will have one to one relationship based on these 4 keys)
full_df = melt_1.merge(melt_2, on=['cust_id', 'cust_first', 'cust_last', 'store'], how='inner')
full_df['city'] = 'New York'
full_df['classification'] = full_df['store'].apply(lambda x: mp[x])
In addition, this method will have its limitation. For example, when one to one relationship is not true based on those four keys, it will generate wrong dataset.
CodePudding user response:
One other way is as follows:
df1 is exactly as df with renamed names ie having the name amount in from of the store value
df1 = (df
.rename(lambda x: re.sub('(.*)_pay', 'pay:\\1', x), axis=1)
.rename(lambda x:re.sub('^(((?!cust|pay).)*)$', 'amount:\\1', x), axis=1))
Now pivot to longer using pd.wide_to_long and do the replacement.
df2 = (pd.wide_to_long(df1, stubnames = ['amount', 'pay'],
i = df1.columns[:3], j = 'store', sep=':', suffix='\\w ')
.reset_index().dropna())
store = {'au_zo':'auto zone', 'fi_gu':'five guys', 'wa':'walmart'}
classification = {'au_zo':'auto-repair', 'fi_gu':'food', 'wa':'groceries'}
df2['classification'] = df2['store'].replace(classification)
df2['store'] = df2['store'].replace(store)
cust_id cust_first cust_last store amount pay classification
0 1000 Andrew Jones auto zone 50.85 debit auto-repair
2 1000 Andrew Jones walmart 69.12 debit groceries
4 1001 Fatima Lee five guys 18.16 debit food
8 1002 Sophia Lewis walmart 159.54. credit groceries
9 1003 Edward Bush auto zone 45.29 credit auto-repair
10 1003 Edward Bush five guys 59.63 credit food
12 1004 Mark Nunez auto zone 20.87 credit auto-repair
13 1004 Mark Nunez five guys 20.87 credit food
14 1004 Mark Nunez walmart 86.18 debit groceries
//NB You could consider using pivot_longer from janitor