I want to add rows in Python based on the information in some of the columns. For example let's say this is my data
df = pd.DataFrame({
'ID':[1,2,3],
'E Test':['Y','Y','N'],
'M Test':['Y','Y','Y'],
})
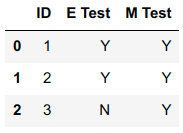
For the row with ID equal to 1, I'd like to add a column that says if the column labeled "E Test" equals "Y" then new column "Test Date" equals "April 1". I'd like to do the same for the "M Test" but with a different date and add a completely new row for the ID equal to 1. Therefore there would be 2 rows that have the ID equal to 1 and with different "Test Date" numbers.
Here is what it would look like ideally:

CodePudding user response:
I use two different dates to show how they can be individually changed.
df2 = df.melt('ID', var_name='Test', value_name='Test Date')
df2['Test'] = df2['Test'].str[0]
df2.replace({'Y': True, 'N': np.nan}, inplace=True)
df2.dropna(inplace=True)
df2.loc[df2['Test'].eq('E'), 'Test Date'] = '1-Apr'
df2.loc[df2['Test'].eq('M'), 'Test Date'] = '2-Apr'
df2 = df2.sort_values('ID').reset_index(drop=True)
print(df2)
Output:
ID Test Test Date
0 1 E 1-Apr
1 1 M 2-Apr
2 2 E 1-Apr
3 2 M 2-Apr
4 3 M 2-Apr
Filtered down to just ID == 1:
print(df2[df2['ID'].eq(1)])
...
ID Test Test Date
0 1 E 1-Apr
1 1 M 2-Apr
CodePudding user response:
Generated test data :
ID E TEST M TEST
0 1 Y Y
1 3 Y N
2 4 Y N
3 5 N Y
4 6 N Y
5 7 Y N
6 8 Y Y
7 9 Y Y
8 10 N Y
Then:
test_dates={'E':'1-Apr','M':'1-May'}
df = df.melt(id_vars='ID').sort_values(['ID','variable']) \
.assign(Test=lambda x: x['variable'].str.slice(0,1)) \
.assign(**{'Test Date': lambda x: x['Test'].map(test_dates)}) \
.loc[lambda x: x['value']=='Y',['ID','Test','Test Date']].reset_index(drop=True)
print(df)
Which results in:
ID Test Test Date
0 1 E 1-Apr
1 1 M 1-May
2 3 E 1-Apr
3 4 E 1-Apr
4 5 M 1-May
5 6 M 1-May
6 7 E 1-Apr
7 8 E 1-Apr
8 8 M 1-May
9 9 E 1-Apr
10 9 M 1-May
11 10 M 1-May