I have a string of key value pairs which I would like to split into a dictionary in Python. With the help of some other questions on here I've been able to put together some regex to achieve this at a single level:
(\S ?):(. ?),
However, a complication I have is that I would like to support sub-pairs, for example, I have this string:
document-name:string,document-type:string,description:string,initiative-name:string,milestone:struct<key:string,name:string>,size:int
This is currently being split like so:
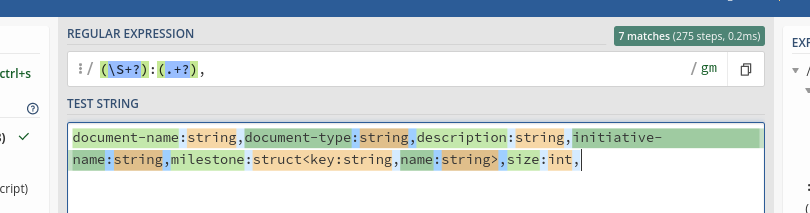
So as you can see it is currently treating the comma in the middle of what is the value of the "milestone" pair as the start of a new pair.
I am planning on using recursion at the code level to deal with this one the splitting has been accomplished successfully, as there is potentially infinite depth. But is there a way I can have it ignore the commas when they are wrapped by brackets, or something similar?
Thanks!
CodePudding user response:
The re library does not support recursion in regular expressions, so either you'd have to import an alternative regular expression library, or you could write a parser that makes the nested dictionary at the same time. This parser would still use a regular expression, but just to tokenise the input. The parser can then use its own stack to apply and verify the nesting.
This solution takes that route:
import re
def parse(s):
regex = r"([^:<>,] ):(?:(struct)<|([^:<>,]*)(>*),?)|(\w |.)"
stack = []
d = {}
for match in re.finditer(regex, s):
key, opening, value, closing, invalid = match.group(1, 2, 3, 4, 5)
if opening:
d[key] = {}
stack.append(d)
d = d[key]
elif invalid:
raise ValueError(f"expected key:value, but found '{invalid}'")
elif not value:
raise ValueError(f"missing value after colon")
else:
d[key] = value
if closing:
if len(closing) > len(stack):
raise ValueError(f"too many '{closing}'")
d = stack[-len(closing)]
del stack[-len(closing):]
if stack:
raise ValueError("missing '>'")
return d
Example call:
s = "document-name:string,document-type:string,description:string,initiative-name:string,milestone:struct<key:string,name:struct<s:string>>,size:int"
d = parse(s)
d will be:
{
'document-name': 'string',
'document-type': 'string',
'description': 'string',
'initiative-name': 'string',
'milestone': {
'key': 'string',
'name': {
's': 'string'
}
},
'size': 'int'
}
CodePudding user response:
As I understood the regex should match milestone as a key and struct<key:string,name:string> as a value. If so then you can use
(\S ?):([^:]*?<.*>|. ?)(?:,|$)
See the regex demo
As the regex above is not the best solution for your problem I decided to provide a Python function to convert such strings to a Python dict.
import re
import json
def convert(string):
string = re.sub(r">", "}", string)
string = re.sub(r"(?<=:)(struct<)", "{", string)
string = re.sub(r"(^|,|{)(.*?)(?=:)", "\\1\"\\2\"", string)
string = re.sub(r"(:)([^{}]*?)(?=$|,|})", "\\1\"\\2\"", string)
return json.loads("{%s}" % string)
NOTE: This works without recursion but works properly
struct = "document-name:string,document-type:string,description:string,initiative-name:string,milestone:struct<foo:struct<a:bar,b:baz>,name:string>,milestone:struct<foo:struct<a:bar,b:baz>,name:string>,size:int"
print(convert(struct)) # {'document-name': 'string', 'document-type': 'string', 'description': 'string', 'initiative-name': 'string', 'milestone': {'foo': {'a': 'bar', 'b': 'baz'}, 'name': 'string'}, 'size': 'int'}
CodePudding user response:
If you want to a capture a single key-value pair with a single regular expression, then you cannot use standard regular expressions, since regular expression do not support recursive structures. You can, however use the regex library, which has added support for recursion.
Your expression could be something like: ([^:<>,] ):(struct\<(?R) \>|[^:<> ] )(,|$|(?=>)).
Breakdown:
([^:<>,] ):- the key and colon(struct\<(?R) \>|[^:<> ] )- the value, either:struct\<(?R) \>- a struct value ((?R)means "recurse" in theregexlibrary)- or a value, e.g.
"string"
(,|$|(?=>))- the ending: must be either a comma, end of input or forward lookahead to a>character.
Here is a more complete parser (pretty much the same regular expression, but using named groups):
import regex
pattern = regex.compile(
r"([^:<>,] ):(struct\<(?P<rec_value>(?R) )\>|(?P<value>[^:<> ] ))(,|$|(?=>))"
)
def parse(s):
return {
match[1]: parse(match["rec_value"]) if match["rec_value"] else match["value"]
for match in pattern.finditer(s)
}
print(
parse(
"document-name:string,document-type:string,description:string,initiative-name:string,milestone:struct<foo:struct<a:bar,b:baz>,name:string>,milestone:struct<foo:struct<a:bar,b:baz>,name:string>,size:int"
)
)
Output:
{
"document-name": "string",
"document-type": "string",
"description": "string",
"initiative-name": "string",
"milestone": {"foo": {"a": "bar", "b": "baz"}, "name": "string"},
"size": "int"
}
Note that this will not error on malformed input, e.g. a:A,b::B,c:C, will just silently ignore the b::B error. A little more work would be needed to catch errors like this.