I am trying to webscrape of 'https://uidb-pbs.tubitak.gov.tr/#tabs-3' website with selenium but I can't get text of neither the table or items of table from web-site. I'm trying to do it like this:
PATH = "C:\Program Files (x86)\chromedriver.exe"
tubitak_ua_driver = webdriver.Chrome(PATH)
tubitak_ua_driver.get("https://uidb-pbs.tubitak.gov.tr/#tabs-3")
project_table = tubitak_ua_driver.find_element_by_xpath('//*[@id="programCagriListTable"]/tbody')
print(project_table.text)
This code doesn't give any error but doesnt give the text either and when I try to get the inner html of the driver I get innerHTML of first tab from website. What is the problem?
CodePudding user response:
Q : Why did your code not work?
The website is poorly designed, there are multiple tables having the same Id in the web page and your code gets the first one which does not have anything inside it. Hence you were getting empty string.
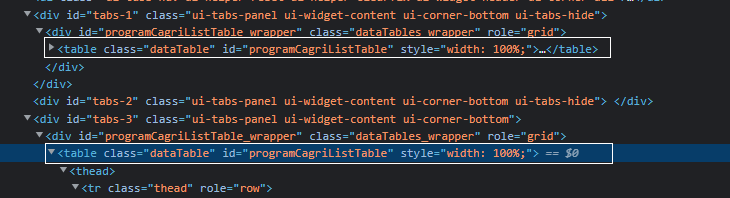
Q : How do we get the desired table.
The desired table is present in the second instance of the query id in your web page. Get the second instance of the returned element and then you can either get the text or load the entire table in a pandas data frame.
table = driver.find_elements_by_xpath('//*[@id="programCagriListTable"]/tbody')
print(table[1].text)
CodePudding user response:
The problem is; there are two elements with this xpath '//*[@id="programCagriListTable"]/tbody' so you need to specify the element that you want. For Example: '(//*[@id="programCagriListTable"]/tbody)[1]'
But if you want the text of an element, you must go to element with text that is
(//table[@id="programCagriListTable"])[2]//descendant::td and to look over with a for