I have a dataframe with two columns for two kinds of rates. But the data inconsistency there has made it difficult to differentiate thousand rates from the normal rates. So, I need to find a pattern of {dot}{3digits} and replace the first dot with blank. So I have created a function to take care of that. But the function is not working as expected and I'm getting an error/warning as below. What could be the issue here?
DF <- data.frame(
PRODUCT_ID = c("A125", "A444", "A744", "B12", "C7", "D1"),
LOC_1 = c("2.000.00 usd pr. kg", "37.61 usd pr. piece", "46.58 usd pr. item", "327%", "0", NA),
LOC_2 = c("45.000.00 usd pr. kg", "3.000.00 usd pr. piece", "780.00 usd pr. item", "505%", "0%", NA)
)
> DF
PRODUCT_ID LOC_1 LOC_2
1 A125 2.000.00 usd pr. kg 45.000.00 usd pr. kg
2 A444 37.61 usd pr. piece 3.000.00 usd pr. piece
3 A744 46.58 usd pr. item 780.00 usd pr. item
4 B12 327% 505%
5 C7 0 0%
6 D1 <NA> <NA>
# function to remove the thousand dots (2.000.00 => 2000.00)
dutyFormat <- function(x) {
if(str_detect(x, '\\.\\d{3}')) {
return(sub('.', '', x, fixed = TRUE))
} else {
return(x)
}
}
DF[,2:3] <- lapply(DF[,2:3], dutyFormat)
Warning messages:
1: In if (str_detect(x, "\\.\\d{3}")) { :
the condition has length > 1 and only the first element will be used
2: In if (str_detect(x, "\\.\\d{3}")) { :
the condition has length > 1 and only the first element will be used
> DF
PRODUCT_ID LOC_1 LOC_2
1 A125 2000.00 usd pr. kg 45000.00 usd pr. kg
2 A444 3761 usd pr. piece 3000.00 usd pr. piece
3 A744 4658 usd pr. item 78000 usd pr. item
4 B12 327% 505%
5 C7 0 0%
6 D1 <NA> <NA>
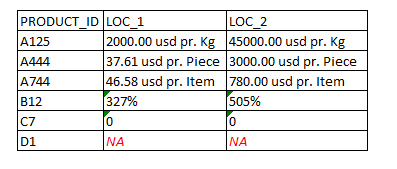
My expected output is this:
CodePudding user response:
Although your if statement did found patterns of '\\.\\d{3}', the subsequent sub operation did not take consideration of that. It will just remove the first dot.
You could use a regex to find out pattern of '\\.\\d{3}', then capture the digits, and replace the whole thing with the capture group (i.e. the digits).
library(dplyr)
DF %>% mutate(across(starts_with("LOC"), ~gsub("\\.(\\d{3})", "\\1", .x)))
PRODUCT_ID LOC_1 LOC_2
1 A125 2000.00 usd pr. kg 45000.00 usd pr. kg
2 A444 37.61 usd pr. piece 3000.00 usd pr. piece
3 A744 46.58 usd pr. item 780.00 usd pr. item
4 B12 327% 505%
5 C7 0 0%
6 D1 <NA> <NA>
CodePudding user response:
You can use stringr::str_replace_all to replace all '.' which are followed by three digits with ''. I used a lookahead for this (see http://www.rexegg.com/regex-lookarounds.html).
DF <- data.frame(
PRODUCT_ID = c("A125", "A444", "A744", "B12", "C7", "D1"),
LOC_1 = c("2.000.00 usd pr. kg", "37.61 usd pr. piece", "46.58 usd pr. item", "327%", "0", NA),
LOC_2 = c("45.000.00 usd pr. kg", "3.000.00 usd pr. piece", "780.00 usd pr. item", "505%", "0%", NA)
)
for (col in colnames(DF)[2:3]) {
DF[[col]] <- stringr::str_replace_all(DF[[col]], '\\.(?=\\d{3})', '')
}
DF
Which gives
PRODUCT_ID LOC_1 LOC_2
1 A125 2000.00 usd pr. kg 45000.00 usd pr. kg
2 A444 37.61 usd pr. piece 3000.00 usd pr. piece
3 A744 46.58 usd pr. item 780.00 usd pr. item
4 B12 327% 505%
5 C7 0 0%
6 D1 <NA> <NA>