I' m beginner in Python.
I have a excel file.
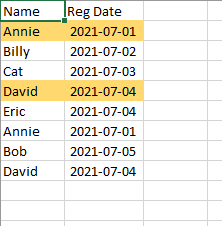
| Name | Reg Date | |Annie | 2021-07-01 | |Billy | 2021-07-02 | |Cat | 2021-07-03 | |David | 2021-07-04 | |Eric | 2021-07-04 | |Annie | 2021-07-01 | |Bob | 2021-07-05 | |David | 2021-07-04 |I found duplicate rows in excel.
Code:
import openpyxl as xl import pandas as pd import numpy as np dt = pd.read_excel('C:/Users/Desktop/Student.xlsx') dt['Duplicate'] = dt.duplicated() DuplicateRows=[dt.duplicated(['Name', 'Reg Date'], keep=False)] print(DuplicateRows)Output:
Name Reg Date Duplicate 1 Annie 2021-07-01 False 6 Annie 2021-07-01 True 4 David 2021-07-04 False 8 David 2021-07-04 TrueAbove I have two questions... Please teach me.
Q1: How to update
Duplicatevalue fromFalsetoTrue?Q2: When
DuplicateisTrue, how to fill background color of rows save inStudent.xlsx?
CodePudding user response:
the duplicated() function itself doesn't have a way to interchange True and False. You can use a NOT operator (~) to so this. Also, used PatternFill to color the relevant rows and write to student.xlsx. Please refer to below code.
Code
import pandas as pd
import numpy as np
from openpyxl.styles import PatternFill
from openpyxl import Workbook
dt = pd.read_excel("myinput.xlsx", sheet_name="Sheet1")
dt['Duplicate'] = dt.duplicated()
dt['Duplicate'] = ~dt[dt.duplicated(['Name', 'Reg Date'], keep=False)].Duplicate
dt['Duplicate'] = dt['Duplicate'].replace(np.nan, False)
print(dt)
wb = Workbook()
ws = wb.active
# Write heading
for i in range(0, dt.shape[1]):
cell_ref = ws.cell(row=1, column=i 1)
cell_ref.value = dt.columns[i-1]
#Write and colot data rows
for row in range(dt.shape[0]):
for col in range(dt.shape[1]):
print(row, col, dt.iat[row, col])
ws.cell(row 2,col 1).value = str(dt.iat[row, col])
if dt.iat[row, 2] == True:
ws.cell(row 2,col 1).fill = PatternFill(start_color='FFD970', end_color='FFD970', fill_type="solid") # change hex code to change color
wb.save('student.xlsx')
Output sheet
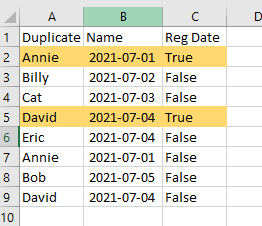
Updated Req
Hi - Please find below the updated code. This will read the data from Student.xlsx Sheet1 and update Sheet2 with the updated colored sheet. If there is NO sheet by that name, it will error out. If there is data in those specific cells in Sheet2, that data will be overwritten, not any other data. Only Name and Reg Date will be written. Post writing to the excel sheet, the dataframe dt's Duplicate column will also be deleted and will only contain the other two columns. Hope this is clear and is what you are looking for...
import pandas as pd
import numpy as np
from openpyxl.styles import PatternFill
from openpyxl import load_workbook
dt = pd.read_excel("Student.xlsx", sheet_name="Sheet1")
dt['Duplicate'] = dt.duplicated()
dt['Duplicate'] = ~dt[dt.duplicated(['Name', 'Reg Date'], keep=False)].Duplicate
dt['Duplicate'] = dt['Duplicate'].replace(np.nan, False)
wb = load_workbook("Student.xlsx")
ws = wb['Sheet2'] # Make sure this sheet exists, else, it will give an error
#Write Heading
for i in range(0, dt.shape[1]-1):
ws.cell(row = 1, column = i 1).value = dt.columns[i]
#Write Data
for row in range(dt.shape[0]):
for col in range(dt.shape[1] - 1):
print(row, col, dt.iat[row, col])
ws.cell(row 2,col 1).value = str(dt.iat[row, col])
if dt.iat[row, 2] == True:
ws.cell(row 2,col 1).fill = PatternFill(start_color='FFD970', end_color='FFD970', fill_type="solid") # used hex code for brown color
wb.save("Student.xlsx")
dt = dt.drop(['Duplicate'], axis=1, inplace=True) # Finally remove the column Duplicated, in case you want to use it
print(dt)
Output Excel