I am trying to do text extraction from some images, however, these come with a bit of background, I have tried to "play" with contrast and brightness, as well as looking to apply thresholding techniques like otsu.
Do you have any suggestions on how to improve the extraction? I leave below some parts of the processing, as well as the input and output, any recommendation will be welcome.
Input:
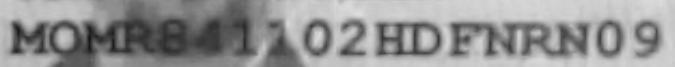
Output:
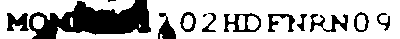
Processing:
enhancer = ImageEnhance.Brightness(img)
img = enhancer.enhance(1.62) # 1.8
enhancer2 = ImageEnhance.Contrast(img)
img = enhancer2.enhance(1.8) # 2
img = np.array(img)
thresh = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
CodePudding user response:
You should perform adaptive threshold. The algorithm divides the image into blocks of pre-defined size. Every block is given a different threshold value based on the pixel intensities within that block. In the following example, threshold is obtained based on Gaussian weight applied to sum of all pixel values within each block (meaning similar pixel values are given more weightage based on Gaussian curve). Binarization is carried out based on this value for each block. Check 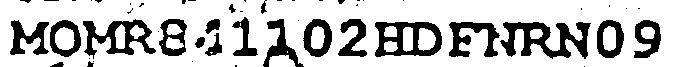
You will have to try tweaking the parameters to get a better result. And also try cv.ADAPTIVE_THRESH_MEAN_C