Goal is to extract unique REGEX matches from string. Issue is eliminating duplicate values in the resulting array.
Consider: Given the following dataframe -
df_inventory = pd.DataFrame([[1000, 'A widget for PEX0043 and PEX7657 in Dept. X7842', 'DPT7843','Part PEX7657'],
[1001, 'A widget for PEX7654 in Depts. X7843, X7842', 'DPT7842','Part PEX7658'],
[1002, 'A widget for PEX7655 PEX7657 in Dept. X7844, X7844, X7842', 'DPT7845','Part PEX7659'],
[1003, 'A widget for PEX7656 PEX7658 in Dept. X7845, X7851, X7850, X7842', 'DPT7844','Part PEX7660'],
[1004, 'A widget for PEX7657 in Dept. X7846', 'DPT7847','Part PEX7661'],
[1005, 'A widget for PEX7658 in Dept. X7847, X7842', 'DPT7846','Part PEX7655'],
[1006, 'A widget for PEX7659 in Dept. X7848, X7842, X7843', 'DPT7849', 'Part PEX7654'],
[1007, 'A widget for PEX7660 in Dept. X7849, X7844', 'DPT7848', 'Part PEX0043'],
[1008, 'A widget for PEX7661 in Dept. X7850', 'DPT7851', 'Part PEX7656'],
[1009, 'A widget for PEX7662 in Dept. X7851,X7842,X7843,X7843,X7845,X7846,X7847', 'DPT7850', 'Part PEX7660']],
columns=['Product ID', 'Description', 'Location','Name'])
We extract using something like:
X_pat = re.compile(r'(?<!PE)(X[0-9]{4})')
df_inventory['X Numbers'] = df_inventory['Description'].str.findall(X_pat).str.join(", ")
When you run this code you find duplicate values in record/row 9:
9 1009 A widget for PEX7662 in Dept. X7851,X7842,X784... DPT7850 Part PEX7660 X7851, X7842, X7843, X7843, X7845, X7846, X7847
I don't think unique is what I need here. Guessing a lamda function.
CodePudding user response:
you can use str.extractall then a lambda on the groups that are returned to get your unique output.
df_inventory['x_numbers'] = df_inventory["Description"]\
.str.extractall("(?<!PE)(X[0-9]{4})")\
.groupby(level=0).agg(
lambda x: ",".join(x.unique())
)
print(df_inventory.drop('Description',axis=1)) # just for a nicer print statement.
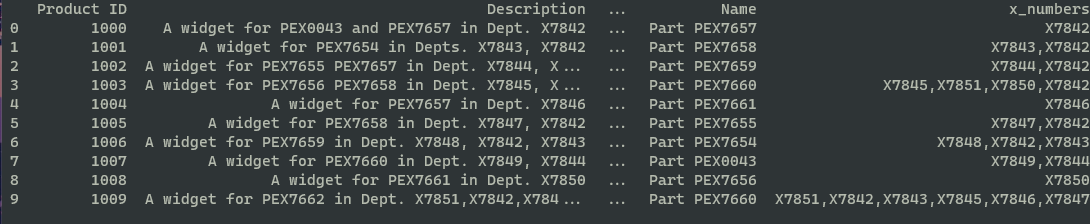
Product ID Location Name x_numbers
0 1000 DPT7843 Part PEX7657 X7842
1 1001 DPT7842 Part PEX7658 X7843,X7842
2 1002 DPT7845 Part PEX7659 X7844,X7842
3 1003 DPT7844 Part PEX7660 X7845,X7851,X7850,X7842
4 1004 DPT7847 Part PEX7661 X7846
5 1005 DPT7846 Part PEX7655 X7847,X7842
6 1006 DPT7849 Part PEX7654 X7848,X7842,X7843
7 1007 DPT7848 Part PEX0043 X7849,X7844
8 1008 DPT7851 Part PEX7656 X7850
9 1009 DPT7850 Part PEX7660 X7851,X7842,X7843,X7845,X7846,X7847