I have a table with 4 columns: ID, STARTDATE, ENDDATE and BADGE. I want to merge rows based on ID and BADGE values but make sure that only consecutive rows will get merged.
For example, If input is:
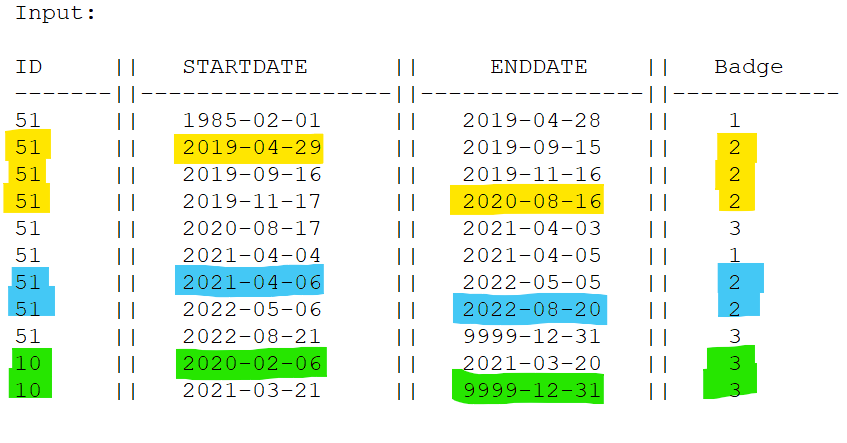
Output will be:
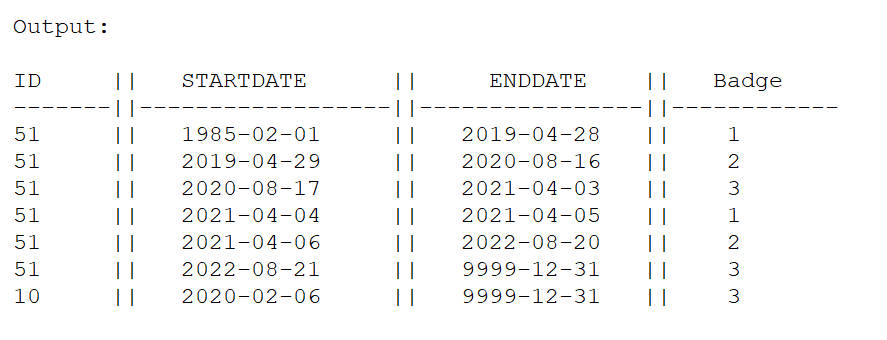
I have tried lag lead, unbounded, bounded precedings but unable to achieve the output:
SELECT ID,
STARTDATE,
MAX(ENDDATE),
NAME
FROM (SELECT USERID,
IFF(LAG(NAME) over(Partition by USERID Order by STARTDATE) = NAME,
LAG(STARTDATE) over(Partition by USERID Order by STARTDATE),
STARTDATE) AS STARTDATE,
ENDDATE,
NAME
from myTable )
GROUP BY USERID,
STARTDATE,
NAME
We have to make sure that we merge only consective rows having same ID and Badge.
Help will be appreciated, Thanks.
CodePudding user response:
You can split the problem into two steps:
- creating the right partitions
- aggregating on the partitions with direct aggregation functions (
MINandMAX)
You can approach the first step using a boolean field that is 1 when there's no consecutive date match (row1.ENDDATE = row2.STARTDATE 1 day). This value will indicate when a new partition should be created. Hence if you compute a running sum, you should have your correctly numbered partitions.
WITH cte AS (
SELECT *,
IFF(LAG(ENDDATE) OVER(PARTITION BY ID, Badge ORDER BY STARTDATE) INTERVAL 1 DAY = STARTDATE , 0, 1) AS boolval
FROM tab
)
SELECT *
SUM(COALESCE(boolval, 0)) OVER(ORDER BY ID DESC, STARTDATE) AS rn
FROM cte
Then the second step can be summarized in the direct aggregation of "STARTDATE" and "ENDDATE" using the MIN and MAX function respectively, grouping on your ranking value. For syntax correctness, you need to add "ID" and "Badge" too in the GROUP BY clause, even though their range of action is already captured by the computed ranking value.
WITH cte AS (
SELECT *,
IFF(LAG(ENDDATE) OVER(PARTITION BY ID, Badge ORDER BY STARTDATE) INTERVAL 1 DAY = STARTDATE , 0, 1) AS boolval
FROM tab
), cte2 AS (
SELECT *,
SUM(COALESCE(boolval, 0)) OVER(ORDER BY ID DESC, STARTDATE) AS rn
FROM cte
)
SELECT ID,
MIN(STARTDATE) AS STARTDATE,
MAX(ENDDATE) AS ENDDATE,
Badge
FROM cte2
GROUP BY ID,
Badge,
rn
CodePudding user response:
In Snowflake, such gaps and island problem can be solved using function conditional_true_event
As below query - First CTE, creates a column to indicate a change event (true or false) when a value changes for column badge.
Next CTE (cte_1) using this change event column with function conditional_true_event produces another column (increment if change is TRUE) to be used as grouping, in the final main query.
And, final query is just min, max group by.
with cte as (
select
m.*,
case when badge <> lag(badge) over (partition by id order by null)
then true
else false end flag
from merge_tab m
), cte_1 as (
select c.*,
conditional_true_event(flag) over (partition by id order by null) cn
from cte c
)
select id,min(startdate) ms, max(enddate) me, badge
from cte_1
group by id,badge,cn
order by id desc, ms asc, me asc, badge asc;
Final output -
| ID | MS | ME | BADGE |
|---|---|---|---|
| 51 | 1985-02-01 | 2019-04-28 | 1 |
| 51 | 2019-04-29 | 2020-08-16 | 2 |
| 51 | 2020-08-17 | 2021-04-03 | 3 |
| 51 | 2021-04-04 | 2021-04-05 | 1 |
| 51 | 2021-04-06 | 2022-08-20 | 2 |
| 51 | 2022-08-21 | 9999-12-31 | 3 |
| 10 | 2020-02-06 | 9999-12-31 | 3 |
With data -
select * from merge_tab;
| ID | STARTDATE | ENDDATE | BADGE |
|---|---|---|---|
| 51 | 1985-02-01 | 2019-04-28 | 1 |
| 51 | 2019-04-29 | 2019-04-28 | 2 |
| 51 | 2019-09-16 | 2019-11-16 | 2 |
| 51 | 2019-11-17 | 2020-08-16 | 2 |
| 51 | 2020-08-17 | 2021-04-03 | 3 |
| 51 | 2021-04-04 | 2021-04-05 | 1 |
| 51 | 2021-04-06 | 2022-05-05 | 2 |
| 51 | 2022-05-06 | 2022-08-20 | 2 |
| 51 | 2022-08-21 | 9999-12-31 | 3 |
| 10 | 2020-02-06 | 2019-04-28 | 3 |
| 10 | 2021-03-21 | 9999-12-31 | 3 |