I just started working on a team project and i have forked the repo which is the main repo, but i guess am missing something in order for me to pull request and i will need assistance...
So i am working on the backend part of the project, spring boot to be precise and am using netbeans 12.4 IDE, so when i forked the main repo, i didnt clone the repo or download the zip and use on my machine (which contained only a license and a readme file) because i had already downloaded a zip file to initialize my spring boot project on the fly from 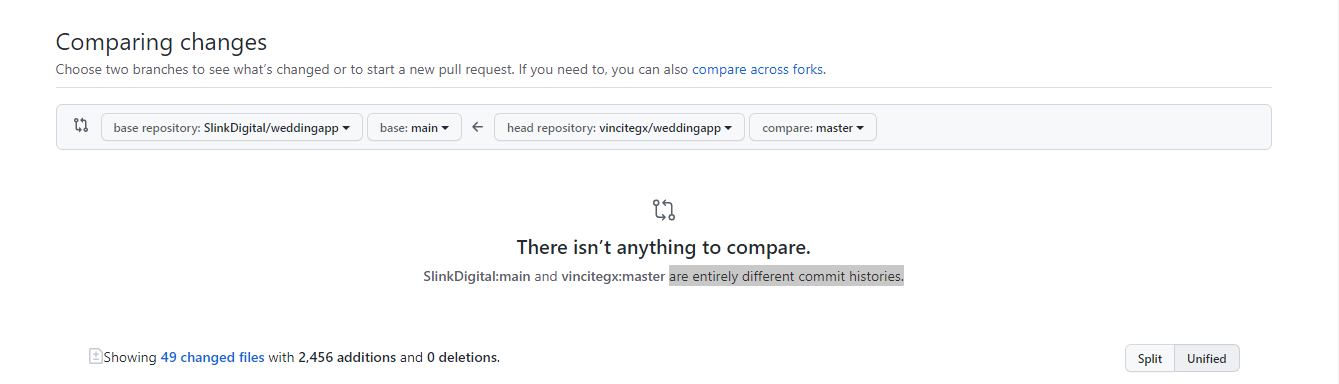
CodePudding user response:
Since its a team project, i assume you have already been added to the repo. You can connect to the main repo by setting the git url to point to the main project, once you've done that, you do a git pull. And then create your personal branch git checkout -b . After that you can push just your branch, then go online and open a pull request from your branch online
CodePudding user response:
... I had already downloaded a zip file
This was the start of all the problems. A zip file is a collection of files, or in other words, a form of archive.
A Git repository is not a collection of files. It's ... well, it is a bit complicated, but to a first approximation, it's a collection of commits where each commit works as an archive. In a way, then, it's almost an archive-of-archives.
Git really focuses heavily on commits, so you need to know what a commit is and does for you:
Each commit is numbered, with a unique, random-looking, very large number, expressed in hexadecimal.
Each commit stores two things: a full snapshot (archive) of every file, plus some extra metadata, or information about this commit itself.
For Git to find a commit, you must give Git the hash ID of that commit. Humans are very bad at hash IDs. In short, we don't want to use them at all, if possible. So, Git gives us (humans) a way to use names instead of the hash IDs. The names actually store hash IDs—each name stores just one, which is all that's required—and when we give Git the name, Git can use a database of name-to-hash-ID mappings to look up the hash ID. Git then feeds the hash ID into the other database it has, where all the commits and other Git objects are stored, looking up the commit from the hash ID.
So a repository is, at a minimum, these two databases:
- One database holds all the commits and other internal Git objects.
- The other database holds names, such as branch and tag names.
A zip file is "half a commit": the archived files, i.e., the snapshot that goes into a commit. Being only half of a commit—missing the metadata part—your downloaded zip file isn't a commit, and when you made a new Git repository, put all your files into the repository's working tree (we'll come back to this in a moment), and used that to make a new commit, you started a new, unrelated history. You are still stuck here now, and to get out of it, you need to take a deep breath, hang on to your existing attempts—they have useful stuff in them—and start over anyway.
Repositories, again
You now know that a repository has, at a minimum, two databases: one holding Git commits and other internal Git objects, and one holding names. A "normal" repository—one in which you do work, on your laptop for instance—has some additional features. These are, on purpose, omitted on special hosting-only repositories like the ones on GitHub, and they have a lot to do with a simple fact: A Git commit, once made, can never be changed.
The magic numbering of commits—the fact that each one gets a unique number, across every Git repository everywhere in the universe—depends on this: it means that two different Git implementations, such as yours on your laptop and the one over on GitHub, will agree that that commit (one you just made, or one you got from someone else) has that hash ID—whatever hash ID it has—and no other commit can have that ID. So if you and they both have the same hash ID, you have the same commit.
In the metadata for any one given commit, Git stores a list of previous commit hash IDs. Most commits store exactly one previous commit ID here. This forms the commits into a single-file "line" or "chain" of commits. Because of the read-only property of commits, the connections from each commit are forced to go backwards: that is, some newer commit whose hash ID is some random-looking number that we'll just call H for short, will store in its metadata, the random-looking number of an earlier commit that we'll just call G for short.
We end up with commit H pointing to (holding the hash ID of) earlier commit G, like this:
<-G <-H
But what's that arrow coming out of G? It's the previous-commit-hash-ID "pointer", pointing to some still-earlier commit F:
... <-F <-G <-H
This whole sequence continues, backwards, all the way to the very first commit ever. That commit doesn't have a previous commit, so its list of "previous commit" hash IDs is just empty. This allows, e.g., the git log command to stop: git log will start at H, show you H, then follow its backwards arrow to G, show you G, follow its arrow to F, and so on, until it gets all the way back to the start (or you quit out of git log).
The tricky bit here is that Git stores the hash ID of H—which it needs to be able to find H—in a branch name. So the picture is more complete if we draw that in:
...--F--G--H <-- main
for instance. The name main points to commit H, which points backwards to G, which points backwards to ... well, by now you know.
This is our key issue, because this backwards chain of commits, as found by some name, is the history in the repository. You're getting the complaint that their repository and your repository have different histories:
There isn't anything to compare.
SlinkDigital:main and vincitegx:master are entirely different commit histories.
And they do, because you made your own separate repository, maybe with one initial commit holding the files you got out of the zip archive, and then maybe added one more commit to it to hold your updated files.
Branches
Let's pause now to talk a bit about branching. Git's way of doing branching is downright weird, if you've used other version control systems. In fact, Git abuses the word branch rather badly, to the point where it doesn't mean anything by itself. We need some extra context to figure out what someone says when they use the word "branch".
We've already pointed out that a branch name, like main or develop, points to one commit. Let's draw a very simple repository with a mere three commits in it, and call them A, B, and C. Commit C will be the newest commit and the last one on the only branch name, main, like this:
A--B--C <-- main
We'll now create a new branch name, develop. Git requires that each branch name hold exactly one hash ID. There are three hash IDs we can choose. Should we use commit A, commit B, or commit C? Well, it usually doesn't hurt much to start with the latest-and-supposedly-greatest, so let's use C:
A--B--C <-- develop, main
Now we have a small problem: now that we have two names, which name are we using right now? Are we on branch develop, as git status would say, or are we on branch main?
The way Git figures this out is to attach the special name HEAD to one of the branch names, like this:
A--B--C <-- develop, main (HEAD)
This means we're on branch main, as git status will say. We're using commit C—because main points to C—but we're using it through the name main.
If we run git checkout develop or git switch develop, the picture changes to:
A--B--C <-- develop (HEAD), main
We're still using commit C, but we're doing so via the name develop now!
If and when we make a new commit—there's more to say about this in a moment—our new commit will get some new, unique, never-used-before hash ID, but we'll just call it D. It will point backwards to existing commit C, because we're using C while making D. It will also hold a new snapshot—a new archive of all files—with the updated files we put into it. And—this is the sneaky trick Git does—when we do make D, Git will update the current branch name, the one with HEAD attached, so that it points to new commit D. So we'll have this:
A--B--C <-- main
\
D <-- develop (HEAD)
If we were now to git switch main or git checkout main to switch back to the branch name main, we would get:
A--B--C <-- main (HEAD)
\
D <-- develop
Git would erase, from our work area, the files that go with commit D, and replace them with the files that go with commit C. So the work we just did would vanish. It's still there: it's in the commit, in the archive in commit D. It's saved there forever (or as long as the commit itself keeps existing anyway), frozen for all time. But it's no longer in the working area. We can now make a new branch name and make another new commit and we'll get:
E <-- new-branch (HEAD)
/
A--B--C <-- main
\
D <-- develop
(Exercise: does it matter if we draw develop on the bottom row and new-branch on the top row like this? What if we flip them around so that D and develop are on the top row and new-branch is on the bottom row?)
Your working tree and Git's index
We have now mentioned several times that the files stored in each commit are all frozen for all time. (So is the metadata: the data and metadata get cryptographically mashed-up to form the hash ID. There's a date-and-time stamp—well, two, really—in each commit to help guarantee the uniqueness, plus the hash ID of the previous commit is in each commit, so if our cryptography is good enough, the hash ID will be unique.)
Not only are committed files read-only, they are also stored in a special Git-only format in which they're compressed—sometimes very compressed—and, crucially, have their contents de-duplicated. This means that if you change one file in a big repository and commit, you're not actually copying all the files, even though the new commit has a copy of all the files. It has de-duplicated copies: all the commits share the duplicates. This is all automatic; you don't have to do anything special; Git does all the work here. But this does mean one thing: You literally can't work on or with the committed files. You have to work on / with copies. Git will read the special Git-ized files and de-compress them and turn them back into usable files, and put these ordinary everyday files into a working area.
Git calls this working area your working tree or work-tree. It has the unpacked archive, and it is quite simply where you do your work. The files in this working area are literally not in Git, even though they may have just come out of Git.
Anyway, you do your work here, in the working tree, and then run git add on any updated or new files to tell Git to prepare them for committing. This uses another thing that's peculiar to Git—that people using other version control systems find strange—that Git calls, variously, the index or the staging area. Some people try to use git commit -a to avoid learning about Git's index / staging-area, but I think this is a bad plan: Git's index keeps popping its little index-y head out in your way now and then, so you need to know about it. But to keep this answer from being even longer, this is about all I'll say about it here: The index-and-working-tree pair are used to make new commits. The index holds your proposed next commit, and you use git add to update it.
(A GitHub repository omits the working tree. The idea is that you'll never work directly on GitHub, so they don't need one. That was true in the past. Since then, GitHub have added some features where you can do work directly on GitHub, which has messed with this idea some, but the lack-of-working-tree on GitHub is still the case. The do-work-on-GitHub stuff is weird and klunky because of this.)
Clones
When you clone a GitHub repository, what you're really doing is:
- creating a new, totally empty repository on your laptop;
- have your laptop Git software, working in your new empty repository—"your Git"—call up GitHub's software working with a repository over on GitHub ("their Git");
- have your Git copy all the commits from their Git.
You don't get all their branch names. In fact, you get no branch names during this copying process. Instead, your Git takes each of their branch names and turns each one into what Git calls a remote-tracking name. Git does this so that any branch name you create from now on will be your branch name, not theirs.
Humans being humans, we like to use the same name on "both sides": we want the same name(s) in our Git here on the laptop that we are using in our GitHub fork. But they're actually different names. In our laptop Git, we use origin/main to remember the name main over in the GitHub Git; when we create a new main in our Git here, it's our main and it can hold a different hash ID. This can get very confusing: it's a good idea to be very careful when saying "branch main" to remember in which Git repository. Fortunately, if you say origin/main, it's pretty clear you're talking about your laptop clone.
Anyway, having copied all the commits, and taken each of your GitHub fork repository branch names and turned them into remote-tracking names like origin/main, your own Git software now creates one branch name in your new clone. The branch name it will create is the one you supply when you run:
git clone -b somebranch <github-URL>
If you don't supply a -b somebranch option, your Git asks their Git what branch name they recommend. Most repositories these days are set up to recommend main (in the old days it was mostly master) and that's the name your Git software will create in your Git repository.
The commit this new name will pick out is the same commit that the same name picks out in the repository over on GitHub right now. But now that you have a new repository—another clone—you have a whole new set of branch names you can use, and each one can be changed to point to different commits!
What's shared are the commits. You'll use git fetch to get new commits from some other repository—new commits someone else made. You'll use git push to send new commits to some other repository. (There's something odd here that's different between fetch and push, but we'll just barely cover it, for space reasons.)
What you need to do now
You need to start with the same history that someone else has.
In general, you do this by forking their repository—it seems like you've already done that. "Forking" is a GitHub-specific thing, although most other hosting sites have the very same concept. It amounts to having GitHub do a git clone for you, on GitHub. There are two special features about this kind of clone though:
Unlike the clone from GitHub to your laptop, this clone copies all the branch names. Once they're copied, they're yours; there's no equivalent of a remote-tracking name and you literally can't update your GitHub fork from their GitHub fork directly any more. (Had GitHub done something like remote-tracking names, you might be able to update it directly, but they didn't so you can't.)
This fork operation also sets up a bunch of GitHub-side behind-the-scenes links between your new GitHub fork and the original repository. These are what allow you to create pull requests in the first place.
Once you have the GitHub-side clone that GitHub call a "fork", you then need to clone your GitHub fork to your laptop.
Note that we now have three clones involved! There's the original repository, your GitHub fork, and your laptop clone. Each clone has its own branch names. It's the commits that we'll share, not the branch names: we only use the branch names to find the commits.
Assuming you did all this cloning fast enough, every one of the three clones has all the same commits. You find your own commits, in your laptop clone, using your branch names. You find copied commits, in your laptop clone, using your remote-tracking names. You find copied, or your own, commits, in your GitHub fork, using your branch names in your GitHub fork. But they'll all share the commits.
Because the commits are the history, all three repositories have exactly the same history. Now you get to add new history to your laptop clone.
In general, they (whoever "they" are—the people whose repository you forked) will have some rule about which of their branches you should do development on. You just made a fork on GitHub, so your GitHub fork has the same branch name pointing to the same commit, and you just cloned that fork to your laptop, so you have a remote-tracking name pointing to the same commit too. So now you just run:
git switch <branch-name>
or:
git checkout <branch-name>
with their branch name. This often (usually?) makes use of a special feature that git switch and git checkout have built in, the "guess" mode. Let's say that they want you to do development on branch dev. Your clone that you just made doesn't have a dev yet, so:
git switch dev
logically ought to give you an error: "I see no name dev, did you mean origin/dev maybe?" But now the --guess option, which is on by default, kicks in. Instead of such an error, Git guesses which origin/* name applies here: it creates a new dev in your laptop repository, pointing to the same commit as origin/dev.
(You can also run git switch -t origin/dev, which doesn't require any guesswork in Git: it means look up the remote-tracking name here and make a new branch using that remote-tracking name. Git finds origin/dev, finds the commit, takes the origin/ part off the remote-tracking name, and tries to create a new dev using the right commit. Some time in the future, if and when you add more than one remote, you may need to use this instead of the guessing mode. But again we'll leave that for later.)
Now that you're on the right branch in your laptop clone of your GitHub fork, now you want to make your changes. You have your saved code from before, and you can use that to make your changes, however you like, including just copying files from the other repository you made (the one with the unrelated history). Use git diff to view the changes you're making, use git add to "stage" them for committing, use git diff --staged to see what's staged, and use git commit to commit the staged changes.
(Technically you're making a whole new snapshot, and the stage actually holds all the files, but when we look at the staging area with git diff --staged or git status, Git only shows us what's different, so that we don't have to go down a checklist of ten thousand files saying "same, uh huh, didn't change, didn't change that one either, that's the same too, right, unchanged, good...". It's much more useful to see what's changed.)
Once you make a new commit on this branch, whatever its name is, you can rename this branch name. Or you can rename it before you commit, or you can make a new branch name before you even start. The name isn't all that important, really! You're going to use the name, but all Git really needs is the hash ID. So let's say you decide you'll make a pull request using the name feature-123. You can do:
git branch -m feature-123
now, after committing, and now instead of:
...--G--H <-- main
\
I--J <-- origin/dev
\
K <-- dev (HEAD)
you now have:
...--G--H <-- main
\
I--J <-- origin/dev
\
K <-- feature-123 (HEAD)
Or, if you make a new branch name feature-123 and switch to it before you make new commit K, you will have:
...--G--H <-- main
\
I--J <-- dev, origin/dev
\
K <-- feature-123 (HEAD)
Note how it doesn't really matter which names you have, as long as you keep straight the idea that "I'm doing my new stuff on ______" (fill in the blank). But we're about to git push and now the names start to matter a little bit.
Now you'll want to send commit K to your GitHub fork, for which you'll use git push. You can do it like this:
git push origin <name-that-finds-K>:<name-you-want-on-GitHub>
for instance:
git push origin HEAD:new-branch
will send commit K to origin (your GitHub fork). That's because HEAD names commit K. Commit K's parent is commit J, so git push would send it, but they say no thanks, I already have that one (you got commit J from them after all!). Your Git software packages up everything for commit K and sends it over, and then asks the GitHub software to create or update the name new-branch in your GitHub fork.
For convenience, if you have already done the branch name trick, you can just run:
git push origin feature-123
Without the colon : character in the middle, your Git software assumes you want the same name on both sides.
Some people really hate coming up with branch names and like to do:
git push origin HEAD:newname
at the very last minute. Some (myself for one) like to come up with the new name in advance.
In all cases, your goal at this point is just this: send the new commit(s) to your GitHub fork and have your GitHub fork create or update some branch name to remember your new commit(s). Your new commits add on to the existing commits, so they join up with the existing history. You can now create a pull request!
Some final notes: setting an upstream
In your laptop clone, each branch can have exactly one upstream setting. The upstream of a branch is just a handy short-cut, but it's often very nice to have the upstream of branch br be origin/br. You can use git branch --set-upstream-to at any time to set the upstream of any branch, with one caveat: the upstream you're setting here, like origin/feature-123, has to exist.
When you create a new branch and git push origin feature-123, the name feature-123 doesn't exist yet on GitHub (you just created it new, just now, on your laptop!) and therefore your laptop, which has origin/* names for each branch name over on GitHub, doesn't have origin/feature-123. So you can't set the upstream of feature-123 until you git push origin feature-123. You could run:
git push origin feature-123
git branch --set-upstream-to=origin/feature-123 feature-123
every time, but that's kind of annoying. So git push has a -u flag:
git push -u origin feature-123
The -u flag means try the git push as usual, and—if and only if it works—then also run git branch --set-upstream-to for me.
You can use this every time, but there's a nice convenient shortcut: by default, git push origin will, since Git version 2.0, push the current branch, under some conditions: the current branch has to have an upstream set, and the upstream name has to match the local name. So once you've done one git push -u origin feature-123 you can follow that up with git push. You won't even need to put in the name origin!
So, the work-flow that I usually use at this point is:
- make a new branch locally
- use a short-cut:
git push -u origin HEAD; my Git resolves the special nameHEADand pushes to the right new branch name on GitHub and sets the upstream for me - from then on, just run
git pushto push the current branch to its upstream.
With the standard settings for push.default, this all works really well. The one minor caveat is that I have to be careful that I'm on the right branch when I run git push with no arguments.
Recap
You need to:
- fork the original repository (probably already done)
- clone your GitHub fork to your computer ("your laptop")
- create an appropriate branch from an appropriate starting commit
- re-do the changes you made earlier
git pushthose to the desired branch name in your GitHub fork (perhaps fussing with branch names some more before or during this step: whatever makes you the most comfortable here)- use the result, which should "just work", to make the pull request
At some point, you will probably need to run git remote add on your laptop clone to add their GitHub repository, and start using git fetch <whatever-name-you-used-for-the-git-remote-command>. This will complicate your life, so don't do it yet!