I have a pandas dataframe below
import pandas as pd
data = {
'id': [1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3],
'datetime': ['2021-03-15', '2021-03-15', '2021-03-17', '2021-03-17', '2021-03-12', '2021-03-12', '2021-12-14', '2021-04-07', '2021-07-09', '2021-04-25', '2021-04-25'],
'n': [1, 2, 1, 2, 1, 2, 1, 1, 1, 1, 2],
't': [1.41, 1.05, 2.01, 0.79, 1.37, 2.19, 1.28, 1.9, 0.97, 1.48, 1.96],
'leq': [73.95284344, 75.08732477, 42.52073186, 14.16069694, 59.36296547, 48.7827182, 44.48691532, 63.63032644, 95.20787662, 61.38061937, 12.50041565]
}
df = pd.DataFrame(data)
and would like to generate daily values for each user using the formula below
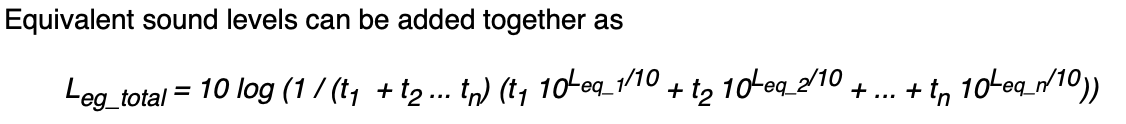
My concern is the varying number of n for each day.
Thanks in advance!
CodePudding user response:
The mathematical formula for your use case would be
10*np.log(1/np.sum(df['t'])*np.sum((df['t']*(np.power(10, df['leq']/10)))))
We want the daily average for each id on each day, which means for id 1 you have 2 unique days 2021-03-15 and 2021-03-17. SO the formula needs to be applied to each group.
df['Daily_Average'] = 0
for group_id, group_df in df.groupby(['id','datetime']):
df.loc[(df['id'] == group_id[0]) & (df['datetime'] == group_id[1]), 'Daily_Average'] = 10*np.log(1/np.sum(group_df['t'])*np.sum((group_df['t']*(np.power(10, group_df['leq']/10)))))
Output:
df
id datetime n t leq Daily_Average
0 1 2021-03-15 1 1.41 73.952843 171.482002
1 1 2021-03-15 2 1.05 75.087325 171.482002
2 1 2021-03-17 1 2.01 42.520732 94.598488
3 1 2021-03-17 2 0.79 14.160697 94.598488
4 2 2021-03-12 1 1.37 59.362965 128.447851
5 2 2021-03-12 2 2.19 48.782718 128.447851
6 2 2021-12-14 1 1.28 44.486915 102.434908
7 3 2021-04-07 1 1.90 63.630326 146.514241
8 3 2021-07-09 1 0.97 95.207877 219.224237
9 3 2021-04-25 1 1.48 61.380619 132.899977
10 3 2021-04-25 2 1.96 12.500416 132.899977
You can set index on id, Date and Daily average for better visibility.
df.set_index(['id', 'datetime', 'Daily_Average', 'n'])
This gives us :
t leq
id datetime Daily_Average n
1 2021-03-15 171.482002 1 1.41 73.952843
2 1.05 75.087325
2021-03-17 94.598488 1 2.01 42.520732
2 0.79 14.160697
2 2021-03-12 128.447851 1 1.37 59.362965
2 2.19 48.782718
2021-12-14 102.434908 1 1.28 44.486915
3 2021-04-07 146.514241 1 1.90 63.630326
2021-07-09 219.224237 1 0.97 95.207877
2021-04-25 132.899977 1 1.48 61.380619
2 1.96 12.500416