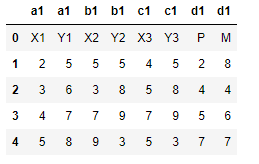
I have the following dataframe:
data={'a1':['X1',2,3,4,5],'Unnamed: 02':['Y1',5,6,7,8],'b1':['X2',5,3,7,9],'Unnamed: 05':['Y2',5,8,9,3],'c1':['X3',4,5,7,5],'Unnamed: 07':['Y3',5,8,9,3],'d1':['P',2,4,5,7],'Unnamed: 09':['M',8,4,6,7]}
df=pd.DataFrame(data)
df.columns=df.columns.to_series().mask(lambda x: x.str.startswith('Unnamed')).ffill()
df
There are a few things which I would like to do:
- Change the rows containing (X1, X2 & X3) into just 'X (vice versa for Y1,Y2,Y3 into 'Y)
- Combine the existing column header with the row containing X,Y,P,M
The outcome should look like:
- Change the rows containing (X1, X2 & X3) into just 'X (vice versa for Y1,Y2,Y3 into 'Y)
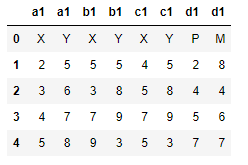
- Combine the existing column header with the row containing X,Y,P,M - Also note that the 'P' and 'M' completely replaces 'd1' respectively.
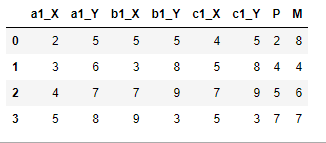
CodePudding user response:
Try this.
import numpy as np
# extract only the letters from first row
first_row = df.iloc[0].str.extract('([A-Z] )')[0]
# update column names by first_row
# the columns with P and M in it have their names completely replaced
df.columns = np.where(first_row.isin(['P', 'M']), first_row, df.columns '_' first_row.values)
# remove first row
df = df.iloc[1:].reset_index(drop=True)
df
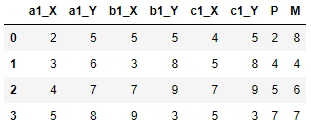
CodePudding user response:
Alternatively, you can do something like this:
# Transpose data frame and make index to column
df = df.T.reset_index()
# Assign new column, use length of first row as condition
df["column"] = np.where(df[0].str.len() > 1, df["index"].str[:] "_" df[0].str[0], df[0].str[0])
df.drop(columns=["index", 0]).set_index("column").T.rename_axis(None, axis=1)
----------------------------------------------------------
a1_X a1_Y b1_X b1_Y c1_X c1_Y P M
1 2 5 5 5 4 5 2 8
2 3 6 3 8 5 8 4 4
3 4 7 7 9 7 9 5 6
4 5 8 9 3 5 3 7 7
----------------------------------------------------------
It's a more general solution as it uses the length of each row-zero entry as a condition, not the actual values 'P' and 'M'. Thus, it holds for each single character string.
CodePudding user response:
df.columns = [x '_' y[0] if len(y)>1 else y for x, y in df.iloc[0].reset_index().values]
df = df[1:].reset_index(drop=True)
print(df)
Output:
a1_X a1_Y b1_X b1_Y c1_X c1_Y P M
0 2 5 5 5 4 5 2 8
1 3 6 3 8 5 8 4 4
2 4 7 7 9 7 9 5 6
3 5 8 9 3 5 3 7 7