My code:
The import requests
The from bs4 import BeautifulSoup
Start=0
Result=[]
The user-agent header={" ", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36}
"For I in range (0, 10) :
Html_1=requests. Get (" https://movie.douban.com/explore#! Type=movie& E7 tag=% % % 83% AD E9%97% A8 & amp; Sort=recommend& Page_limit=20 & amp; Page_ "+ STR (start) +"=0 ", headers=headers)
Html_1. Encoding="utf-8"
Start +=25
Soup=BeautifulSoup (html_1. Text, ". The HTML parser ")
For the item in soup. Find_all (" div ", "list - wp) :
The item=item. Div. A.P.S tring
Print (item)
Part of the source code of your page:
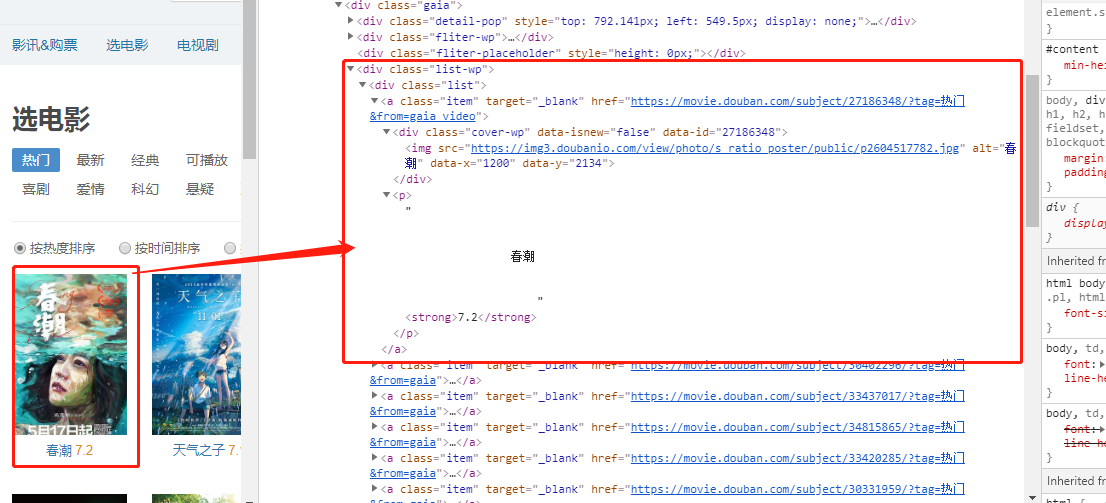
But enforcement is displayed: AttributeError: 'NoneType' object has no attribute 'p',
If I delete the "p", becomes a 'NoneType' object has no attribute 'string'
Ahhh crazy
In addition, I also found that there is a strange place, I check my web site source code, Google is not show all the code, so I just looked in the element of view, is the place to see in the screenshot, is affected by this? A great god ~ ~ o help solve