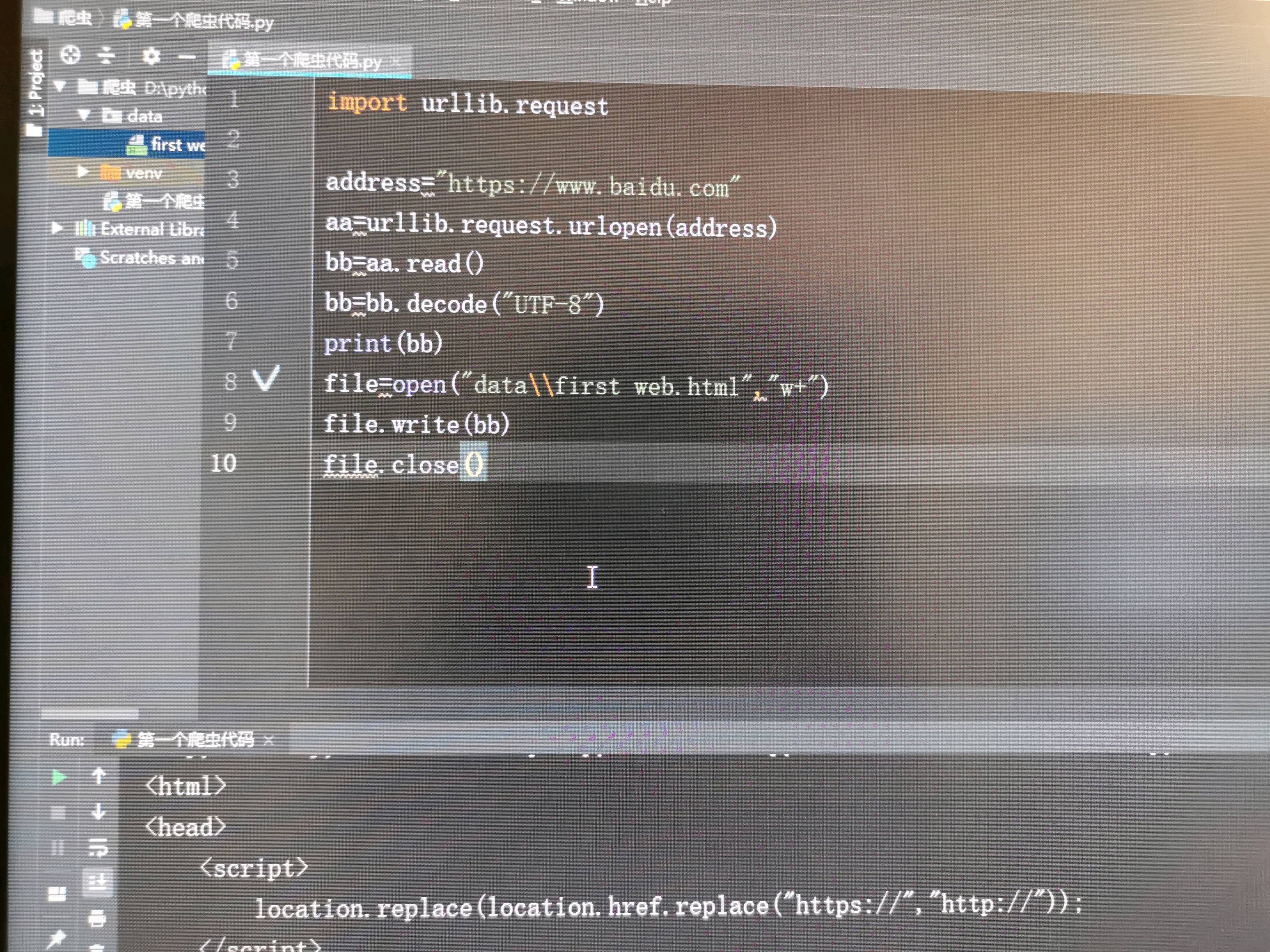
Why won't open the web page?
CodePudding user response:
Do you want to store the contents of the crawl into a. HTML file, but the path to the file you have any question! Either write an absolute path, or write a relative path! You seem to write wrong!
CodePudding user response:
reference 1st floor il_ perserve _li reply: do you want to store the contents of the crawl into a. HTML file, but the path to the file you have any question! Either write an absolute path, or write a relative path! You seem to write wrong! CodePudding user response:
It seems I didn't understand what you want to speak, the beginning CodePudding user response:
reference il_ perserve _li reply: 3/f I don't understand what you want to speak, the beginning CodePudding user response:
Oh oh, that is like CodePudding user response:
Baidu this site if you need to add a request header, or climb on the content of no actual so much, but not achieve the search after open this web page CodePudding user response:
Advice is requests request connection