The from bs4 import BeautifulSoup
The import openpyxl
The import time
# the from selenium.webdriver.com mon. Keys import keys
# initialization browser
Browser=webdriver. Chrome (' chromedriver_win32/chromedriver. Exe)
# structured data list
Position_list=[]
Def get_position_list (url) :
The get (url)
# huoq access web page source code
Html_doc=the page_source
# use beautisoup parsing the web structure, object into soup
Soup=BeautifulSoup (html_doc, '. The HTML parser)
# print (soup. The title)
# locate elements, extract the key information
# get all entries li
# div_docs=soup. Select (' el ')
# li_doc=li_docs [0]
All_list1={}
Def get_job_info () :
All_list=the find_element_by_id (" resultList "). Find_elements_by_class_name (" el ")
# structured data list
Position_list=[]
Every entry # traverse the current page
For div_doc all_list in [1] :
# print (li_doc attrs)
# data cleaning, structured
The position={}
# get li tag attribute values
# attrs=div_doc. Attrs
Position [' positionname]=div_doc. Select_one (' t1 '), find (' a '). The string
Position [' company ']=div_doc. Select_one (' t2 '), find (' a '). The string
Position [' district ']=div_doc. Select_one (' t3 '). The string
Position [' salary ']=div_doc. Select_one (' t4 '). The string
Position [' public_date]=div_doc. Select_one (' 0 '). The string
Position_list. Append (position)
# print (position_list)
Return position_list
Return all_list1
To keep # Excel
# to open the Excel
Wb=openpyxl. Workbook ()
# orientation to the current formWs=wb. Active
# set the header
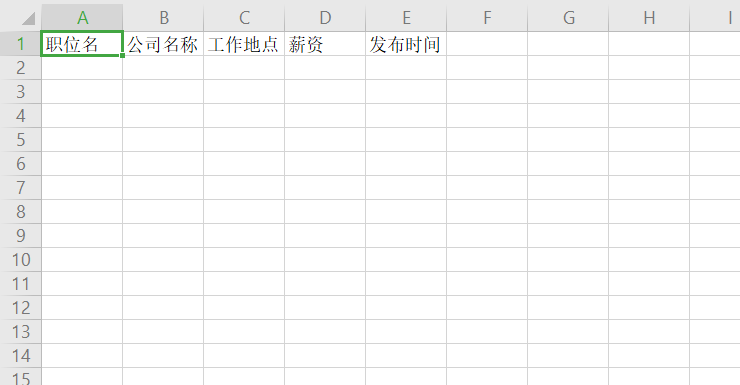
Head_row=[' position ',
'company name'
'work',
'wages'
'release time,
]
Ws. Append (head_row)
# page, get all the data
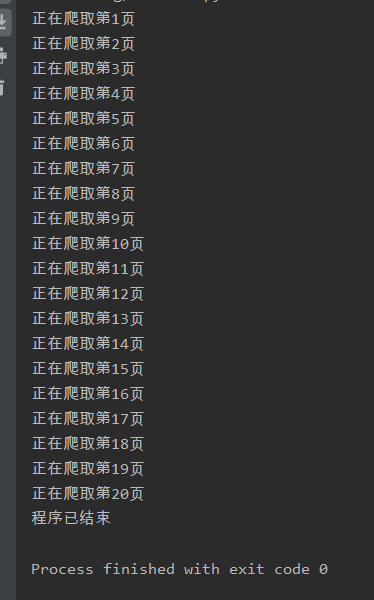
For I in range (1, 21) :
Print (' climbing in the first page {0} '. The format (I))
# to open the target site, python search results page
Url='https://search.51job.com/list/070300, 000000000 0,00,9,99, python, 2, {0}. The HTML? '. The format (I)
# list=get_position_list (url)
The get (url) # open website
# print (list)
For the position in position_list:
Data_row=[
Position [' positionname],
Position [' company '],
Position [' district '],
Position [' salary '],
Position [' public_data],
]
Ws. Append (data_row)
# crawl a page, wait for 3 seconds, climb in the next page
Time. Sleep (3)
# save Excel
Wb. Save (' 51 job position data acquisition. XLSX)
# close the browser
Print (' program has ended)
The close ()
CodePudding user response:
CodePudding user response:
A little more you this question, didn't call the processing function? How to get the data, just a run a print circulation, and the processing function get_position_list... no nested functions, two public_date public_data a e an a is hereCodePudding user response:
# - * - coding: utf-8 - * -
The from the selenium import webdriver
The from bs4 import BeautifulSoup
The import openpyxl
The import time
Browser=webdriver. Chrome (r 'D: \ chromedriver_win32 \ chromedriver. Exe)
# structured data list
Def get_position_list (url) :
The get (url)
Html_doc=the page_source
LXML soup=BeautifulSoup (html_doc, the features=' ')
All_list=soup. The find (' div ', 'dw_table). Find_all (' div', 'el)
Position_list=[]
For div_doc all_list in [1] :
The position={}
Position [' positionname]=div_doc. Select_one (' t1 '), find (' a '). String. Strip ()
Position [' company ']=div_doc. Select_one (' t2 '), find (' a '). String. Strip ()
Position [' district ']=div_doc. Select_one (' t3 '). The string. The strip ()
Position [' salary ']=div_doc. Select_one (' t4 '). The string
Position [' public_date]=div_doc. Select_one (' 0 '). The string. The strip ()
Position_list. Append (position)
Return position_list
Wb=openpyxl. Workbook ()
# orientation to the current formWs=wb. Active
# set the header
Head_row=[' position ',
'company name'
'work',
'wages'
'release time,
]
Ws. Append (head_row)
For I in range (1, 3) :
Print (' climbing in the first page {0} '. The format (I))
# to open the target site, python search results page
Url='https://search.51job.com/list/070300, 000000000 0,00,9,99, python, 2, {0}. The HTML? '. The format (I)
List=get_position_list (url)
For the position in the list:
Data_row=[
Position [' positionname],
Position [' company '],
Position [' district '],
Position [' salary '],
Position [' public_date]
]
Ws. Append (data_row)
# crawl a page, wait for 3 seconds, climb in the next page
Time. Sleep (3)
# save Excel
Wb. Save (' 51 job position data acquisition. XLSX)
# close the browser
Print (' program has ended)
The quit ()
This version can be used, the problem is we had