I wanted to use python code to download the web page, view the source code, download link is
Href="https://bbs.csdn.net/dl/705673/bea2bd"
Point in can download
But I python code to climb to the
/dl/705673/19017 a
Cannot download file
The code below
Headers={
"The user-agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 "
}
The response=requests. Get (url, headers=headers)
Print (the response headers)
# print (response. The content)
Soup=BeautifulSoup (response. The content, "LXML")
Print (soup)
With F12 looked at it and when I click on the download, can appear below
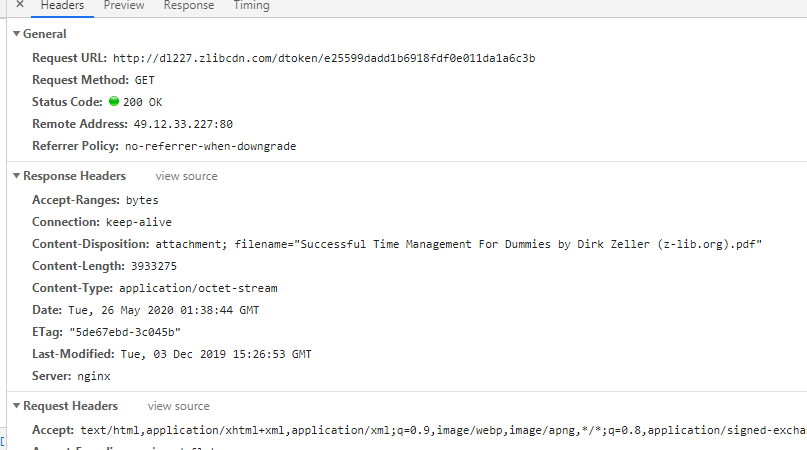
Tried it on, the inside of the url is open the download
http://dl219.zlibcdn.com/dtoken/04a9c8e8420fa472c6301b70c2afeb75
But every click download, a different URL
Consult everybody great god how to solve?
CodePudding user response:
You crawl to the link, you climb the link is not full, you F12, the mouse on the links can be seen on the front part to supplement the download link is normal,You have climbed, do more step processing
CodePudding user response:
It is ok to add url first halfCodePudding user response:
Link may not be complete, you add together