I'm working with PySpark. I have a dataset like this:
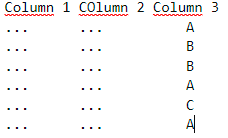
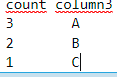
I want to count lines of my dataset in function of my "Column3" column. For example, here I want to get this dataset:
CodePudding user response:
temp = spark.createDataFrame([
(0, 11, 'A'),
(1, 12, 'B'),
(2, 13, 'B'),
(0, 14, 'A'),
(1, 15, 'c'),
(2, 16, 'A'),
], ["column1", "column2", 'column3'])
temp.groupBy('column3').agg(count('*').alias('count')).sort('column3').show(10, False)
# ------- -----
# |column3|count|
# ------- -----
# |A |3 |
# |B |2 |
# |c |1 |
# ------- -----
CodePudding user response:
df.groupBy('column_3').count()