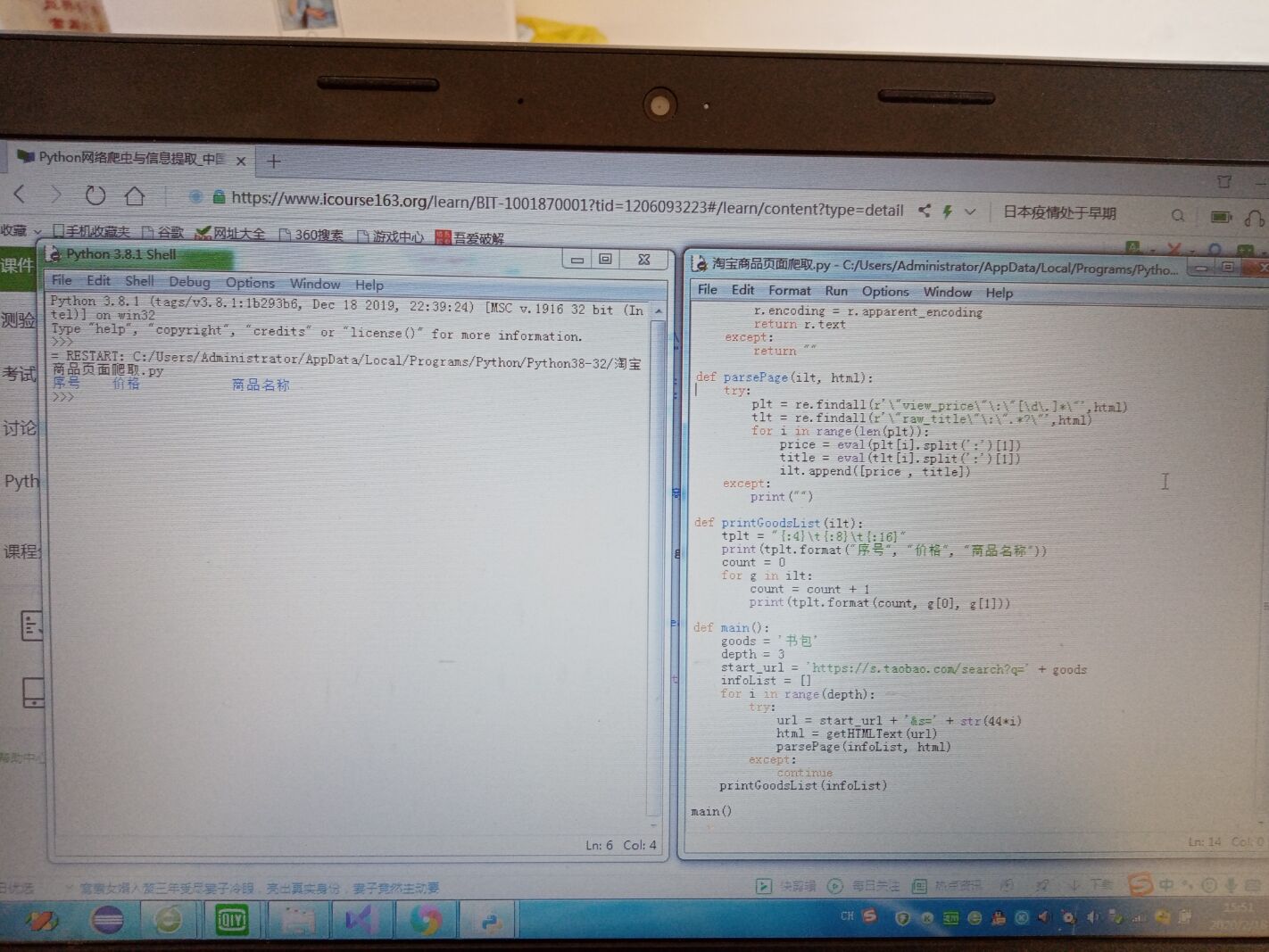
The import re
Def getHTMLText (url) :
Try:
R=requests. Get (url, timeout=30)
R.r aise_for_status ()
R.e ncoding=of state Richard armitage pparent_encoding
Return r.t ext
Except:
Return ""
Def parsePage (ilt, HTML) :
Try:
PLT=re. The.findall (r "" view_price \ \ ": " [\ d \] * \ ', HTML)
TLT=re. The.findall (r '\ "raw_title \ " : \ ". *? \ ', HTML)
"For I in range (len (PLT)) :
Price=eval (PLT [I]. The split (' : ') [1])
Title=eval (TLT [I]. The split (' : ') [1])
Ilt. Append ([price, the title])
Except:
Print (" ")
Def printGoodsList (ilt) :
TPLT=": {4} {: 8} \ \ t t {: 16}"
Print (TPLT. The format (" serial number ", "price", "name of commodity"))
The count=0
For g in ilt:
The count=count + 1
Print (TPLT. The format ([0] count, g, g [1]))
Def the main () :
Goods='bag'
The depth=3
Start_url='https://s.taobao.com/search? Q='+ goods
InfoList=[]
For I in range (the depth) :
Try:
Url=start_url + '& amp; S='+ STR (44 * I)
HTML=getHTMLText (url)
ParsePage (infoList, HTML)
Except:
The continue
PrintGoodsList (infoList)
The main ()