I am a bit confused about the output shape of the convolutional layer. For example, as the image showed, 2 filters for 663 images, finally output will be 442, which the three color channel will fuse to 1 layer, but in some network after the convolution layer, the color channel still keep, for example here model.add(Conv2D(32, kernel_size=5,strides=1, activation=None, input_shape=(128,128,3))), the output shape of this is conv2d_5 (5, 5, 3, 32), and the question is I didn't see any specific code to say color channel keep or not.
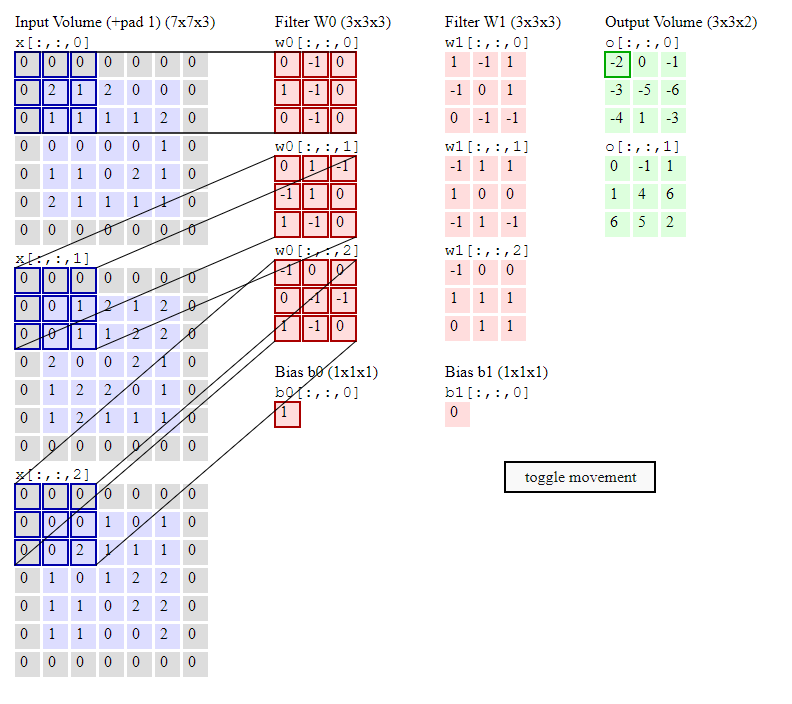
then the output element is computed as:
import numpy as np
# filter weights of size 3 x 3 x 3
w0 = np.array([
[[0., -1., 0.],
[1., -1., 0.],
[0., -1., 0.]],
[[0., 1., -1.],
[-1., 1., 0.],
[1., -1., 0.]],
[[-1., 0., 0.],
[0., -1., -1.],
[1., -1., 0.]]
])
# bias value for the filter
b0 = 1
# an input image patch 3 x 3 x 3
x_patch = np.array([
[[0., 0., 0.],
[0., 2., 1.],
[0., 1., 1.]],
[[0., 0., 0.],
[0., 0., 1.],
[0., 0., 1.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 2.]]
])
# define the operation for each channel
>>> op = lambda xs, ws: np.sum(xs*ws)
>>> op(x_patch[:, :, 0], w0[:, :, 0]) # channel 1
0.0
>>> op(x_patch[:, :, 1], w0[:, :, 1]) # channel 2
-3.0
>>> op(x_patch[:, :, 2], w0[:, :, 2]) # channel 3
0.0
# add the values for each channel (this is where
# channel dimension is summed over) plus the bias
>>> 0.0 (-3.0) 0.0 b0
-2.0
# or simply
>>> np.sum(x_patch * w0) b0
-2.0
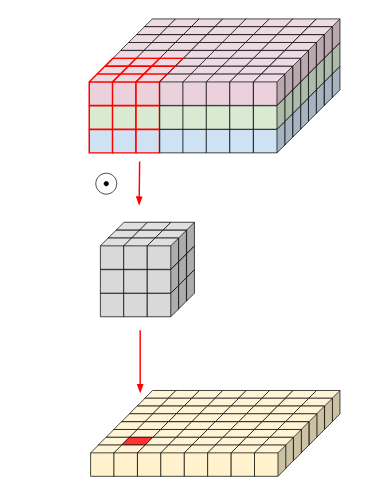
This is generally the case for CNN, which can alterantively be visualized as
compared to Depth-wise convolution where the channel dimension is kept as is:
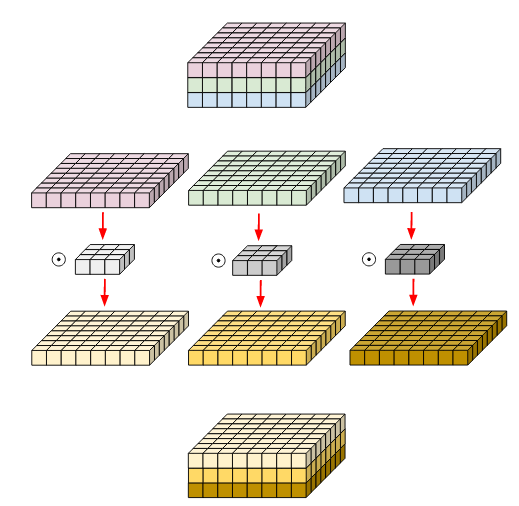
TensorFlow provides separate implementations for each in tf.keras.layers.Conv2D (here) and tf.keras.layers.DepthwiseConv2D (here) so you can use according to your application.
I cannot reproduce the output dimension of 5 x 5 x 3 x 32 for your second example (using tf v2.9.0):
import tensorflow as tf
# The inputs are 128 x 128 RGB images with
# `data_format=channels_last` (by default) and
# the batch size is 4.
>>> input_shape = (4, 128, 128, 3)
>>> x = tf.random.normal(input_shape)
>>> y = tf.keras.layers.Conv2D(
32,
kernel_size=5,
strides=1,
activation=None,
input_shape=(128, 128, 3)
)(x)
>>> print(y.shape)
(4, 124, 124, 32)
The example code is slightly adjusted from the official documentation example.
CodePudding user response:
model = Sequential()
model.add(Conv2D(32, kernel_size=5,strides=1, activation=None, input_shape=(128,128,3)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPool2D(2,2))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(64,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1))
model.add(Activation('sigmoid'))
for layer in model.layers:
# check for convolutional layer
if 'conv' not in layer.name:
continue
# get filter weights
filters, biases = layer.get_weights()
print(layer.name, filters.shape)
so when I print the conv output layer shape it shows as conv2d_46 (5, 5, 3, 32). when I print the summary the out shape show different, what is None? Layer (type) Output Shape Param #
conv2d_45 (Conv2D) (None, 124, 124, 32) 2432
batch_normalization_38 (Bat (None, 124, 124, 32) 128
chNormalization)
activation_36 (Activation) (None, 124, 124, 32) 0
max_pooling2d_17 (MaxPoolin (None, 62, 62, 32) 0
g2D)
dropout_26 (Dropout) (None, 62, 62, 32) 0
flatten_11 (Flatten) (None, 123008) 0
dense_23 (Dense) (None, 64) 7872576
dropout_27 (Dropout) (None, 64) 0
dense_24 (Dense) (None, 1) 65
activation_37 (Activation) (None, 1) 0