I have a small sample of my dataframe here:
df = pd.DataFrame([[1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1], [0, 0, 0, 0]], columns = ["CHAP1SEC1", "CHAP1SEC2", "CHAP1SEC3", "CHAP1SEC4", "CHAP1SEC5"], index = [0, 1, 2, 3])
Note: the variables are binary.
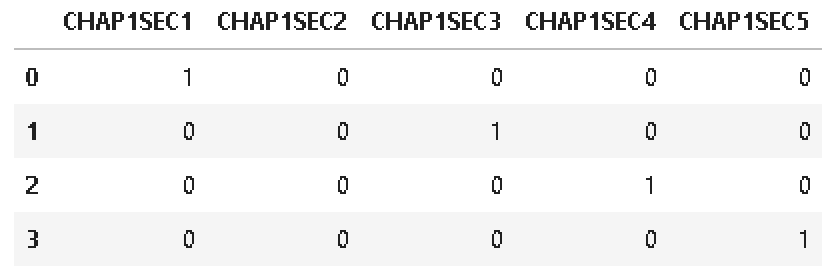
I'm trying to essentially merge these 4 rows into one row, keeping any non-zero entries in the columns. Since the variables are binary, my go-to was just to take column sums.
df.sum(axis = 1)
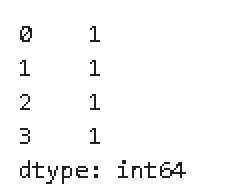
However, while this gives me the values I want, it is not returned in the same original dataframe structure.
Essentially, I would like to take the column sums of a dataframe, while keeping the structure of that dataframe. Ideally, my output would be as follows:
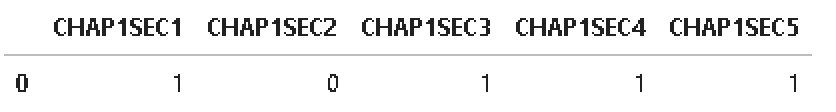
I feel there must be a super simple solution that I am just not seeing and I couldn't find a similar question already posted on SO.
Any help is appreciated!
CodePudding user response:
here is one way to do it
df.sum(axis=0).to_frame().T
or
df.sum().to_frame().T
CHAP1SEC1 CHAP1SEC2 CHAP1SEC3 CHAP1SEC4 CHAP1SEC5
0 1 0 1 1 1