I have a dataframe with 0 and 1 and I would like to count groups of 1s (don't mind the 0s) with a Pandas solution (not itertools, not python iteration).
Other SO posts suggest methods based on shift()/diff()/cumsum() which seems not to work when the leading sequence in the dataframe starts with 0.
df = pandas.Series([0,1,1,1,0,0,1,0,1,1,0,1,1]) # should give 4
df = pandas.Series([1,1,0,0,1,0,1,1,0,1,1]) # should also give 4
df = pandas.Series([1,1,1,1,1,0,1]) # should give 2
Any idea ?
CodePudding user response:
If you only have 0/1, you can use:
s = pd.Series([0,1,1,1,0,0,1,0,1,1,0,1,1])
count = s.diff().fillna(s).eq(1).sum()
output: 4 (4 and 2 for the other two)
Then fillna ensures that Series starting with 1 will be counted
faster alternative
use the diff, count the 1 and correct the result with the first item:
count = s.diff().eq(1).sum() (s.iloc[0]==1)
comparison of different pandas approaches:
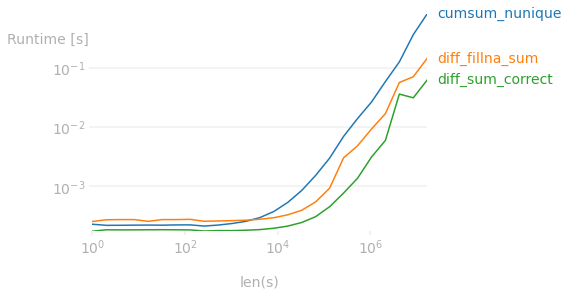
CodePudding user response:
Let us identify the diffrent groups of 1's using cumsum, then use nunique to count the number of unique groups
m = df.eq(0)
m.cumsum()[~m].nunique()
Result
case 1: 4
case 2: 4
case 3: 2