I have the following dataframe. I want to only keep the group if the group has no zero in the "value" column. My current dataframe looks like the following.
ID date value
A 2020Q1 5
A 2020Q2 5
A 2020Q3 7
A 2020Q4 6
A 2021Q1 9
B 2019Q1 4
B 2019Q2 0
B 2019Q3 9
C 2019Q1 3
C 2019Q2 2
C 2019Q3 2
C 2019Q4 0
D 2019Q3 7
D 2019Q4 7
D 2020Q1 8
E 2020Q1 1
E 2020Q2 1
E 2020Q3 1
E 2020Q4 5
F 2018Q1 7
F 2018Q2 8
F 2018Q3 8
G 2018Q1 0
G 2018Q2 0
G 2018Q3 4
G 2018Q4 8
..
I want to drop the whole group if the group's value contains zero.
the desired output is
ID date value
A 2020Q1 5
A 2020Q2 5
A 2020Q3 7
A 2020Q4 6
A 2021Q1 9
D 2019Q3 7
D 2019Q4 7
D 2020Q1 8
E 2020Q1 1
E 2020Q2 1
E 2020Q3 1
E 2020Q4 5
F 2018Q1 7
F 2018Q2 8
F 2018Q3 8
..
thanks.
CodePudding user response:
We could use a groupby filter:
df.groupby('ID').filter(lambda x: not any(x['value'] == 0))
Output
ID date value
0 A 2020Q1 5
1 A 2020Q2 5
2 A 2020Q3 7
3 A 2020Q4 6
4 A 2021Q1 9
12 D 2019Q3 7
13 D 2019Q4 7
14 D 2020Q1 8
15 E 2020Q1 1
16 E 2020Q2 1
17 E 2020Q3 1
18 E 2020Q4 5
19 F 2018Q1 7
20 F 2018Q2 8
21 F 2018Q3 8
Data:
import pandas as pd
from io import StringIO
data = StringIO("""
ID,date,value
A,2020Q1,5
A,2020Q2,5
A,2020Q3,7
A,2020Q4,6
A,2021Q1,9
B,2019Q1,4
B,2019Q2,0
B,2019Q3,9
C,2019Q1,3
C,2019Q2,2
C,2019Q3,2
C,2019Q4,0
D,2019Q3,7
D,2019Q4,7
D,2020Q1,8
E,2020Q1,1
E,2020Q2,1
E,2020Q3,1
E,2020Q4,5
F,2018Q1,7
F,2018Q2,8
F,2018Q3,8
G,2018Q1,0
G,2018Q2,0
G,2018Q3,4
G,2018Q4,8
""")
df = pd.read_csv(data, sep = ",")
CodePudding user response:
You could check for rows where value is 0 and get the 'ID' value (mask). Then filter the df with it:
mask = df.loc[df['value'].eq(0), 'ID'].unique()
# mask looks like this: ['B' 'C' 'G']
result = df.loc[~df['ID'].isin(mask),:]
Output result:
ID date value
0 A 2020Q1 5
1 A 2020Q2 5
2 A 2020Q3 7
3 A 2020Q4 6
4 A 2021Q1 9
12 D 2019Q3 7
13 D 2019Q4 7
14 D 2020Q1 8
15 E 2020Q1 1
16 E 2020Q2 1
17 E 2020Q3 1
18 E 2020Q4 5
19 F 2018Q1 7
20 F 2018Q2 8
21 F 2018Q3 8
CodePudding user response:
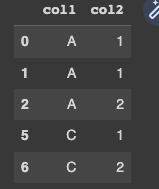
Check Below code
import pandas as pd
import numpy as np
df = pd.DataFrame({'col1':['A','A','A','B','B','C','C'],'col2':[1,1,2,0,1,1,2]})
df[df.groupby('col1')['col2'].transform('min') > 0]
Output:
CodePudding user response:
I think you can do it without groupby:
ids_to_delete = df.ID[df.value == 0].unqiue()
df = df.query("~(ID in @ids_to_delete)")
CodePudding user response:
You can use apply and df.drop to remove your undesired group (If you ID is actually your index)
condition = df[df.groupby("ID")['value'].apply(lambda x:x == 0)].index.unique()
df.drop(condition, inplace=True)
CodePudding user response:
cond = df.loc[df['value'] == 0]['ID'].unique()
for index in cond:
for i in df.index:
if df.loc[i,'ID'] == index:
df.drop(index = i, inplace= True)
df
Or Simply (Shortcut version of above)
cond = df.loc[df['value'] == 0]['ID'].to_list()
df.drop(cond, inplace=True)
df