I have a pandas dataframe like this:
col
0 3
1 5
2 9
3 5
4 6
5 6
6 11
7 6
8 2
9 10
that could be created in Python with the code:
import pandas as pd
df = pd.DataFrame(
{
'col': [3, 5, 9, 5, 6, 6, 11, 6, 2, 10]
}
)
I want to find the rows that have a value greater than 8, and also there is at least one row before them that has a value less than 4.
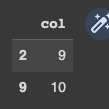
So the output should be:
col
2 9
9 10
You can see that index 0 has a value equal to 3 (less than 4) and then index 2 has a value greater than 8. So we add index 2 to the output and continue to check for the next rows. But we don't anymore consider indexes 0, 1, 2, and reset the work.
Index 6 has a value equal to 11, but none of the indexes 3, 4, 5 has a value less than 4, so we don't add index 6 to the output.
Index 8 has a value equal to 2 (less than 4) and index 9 has a value equal to 10 (greater than 8), so index 9 is added to the output.
It's my priority not to use any for-loops for the code.
Have you any idea about this?
CodePudding user response:
Boolean indexing to the rescue:
# value > 8
m1 = df['col'].gt(8)
# get previous value <4
# check if any occurred previously
m2 = df['col'].shift().lt(4).groupby(m1[::-1].cumsum()).cummax()
df[m1&m2]
Output:
col
2 9
9 10
CodePudding user response:
Check Below code using SHIFT:
df['val'] = np.where(df['col']>8, True, False).cumsum()
df['val'] = np.where(df['col']>8, df['val']-1, df['val'])
df.assign(min_value = df.groupby('val')['col'].transform('min')).\
query('col>8 and min_value<4')[['col']]
OUTPUT: