this is my df
a = [1,3,4,5,6]
b = [5,3,7,8,9]
c = [0,7,34,6,87]
dd = pd.DataFrame({"a":a,"b":b,"c":c})
I need the output such that first row of the df remains the same, and for all subsequent rows the value in column b = value in column a value in column b in the row just above the value in column c
i.e. dd.iloc[1,1] will be 15 (i.e. 3 5 7)
dd.iloc[2,1] will be 53 (i.e. 4 15 34) plz note that it took new value of [1,1] i.e. 15 (instead of the old value which was 3)
dd.iloc[3,1] will be 64 (5 53 6). Again it took the updated value of [2,1] (i.e. 53 instead of 7)
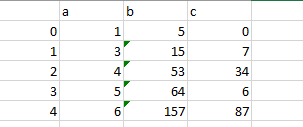
expected output
CodePudding user response:
Use:
from numba import jit
@jit(nopython=True)
def f(a,b,c):
for i in range(1, a.shape[0]):
b[i] = b[i-1] a[i] c[i]
return b
dd['b'] = f(dd.a.to_numpy(), dd.b.to_numpy(), dd.c.to_numpy())
print (dd)
a b c
0 1 5 0
1 3 15 7
2 4 53 34
3 5 64 6
4 6 157 87