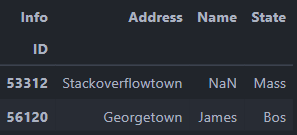
I have the below dataframe with data that looks like this:(Made up data for clarification)
| Info | Values |
|---|---|
| ID | 53312 |
| State | Mass |
| Address | Stackoverflowtown |
| ID | 56120 |
| State: | Bos |
| Address | Georgetown |
| Name: | James |
There are a lot of lines but the issue I am having is that I want the data that is under a certain ID to be in width form because ID, State, Address belong to the same ID- then for the next line where we also have a Name (ID, State, Address, Name) all belong to the same ID.
Question: Is there a way using Python Pandas or Excel to make it so that table would look something more like this:(Where we use ID as the index)
| ID | State | Address | Name |
|---|---|---|---|
| 53312 | Mass | Stackoverflowtown | |
| 56120 | Bos | Georgetown | James |
I tried to do a pivot in Python but the issue is that since the values are all originally under the same column , when pivoted for me they end up showing each Value (ID, sTATE, Address..etc) on a different line and values in the same line would be blank- it looks something like this which is not right:
Example for ID 53312:
| ID | State | Address | Name |
|---|---|---|---|
| 53312 | Null | Null | Null |
| Null | Mass | NULL | NULL |
| Null | NULL | Stackoverflowtown | NULL |
| Null | NULL | NULL | NULL |
CodePudding user response:
Check Below Code:
import pandas as pd
df = pd.DataFrame({'Info':['ID','State','Address','ID','State','Address','Name'],
'Values':[53312,'Mass','Stackoverflowtown',56120,'Bos','Georgetown','James']})
df['cumcount'] = df.groupby('Info')['Info'].transform('cumcount')
df['cumcount'] = np.where(df['cumcount'] < df['cumcount'].shift(), df['cumcount'].shift(), df['cumcount'])
pd.pivot_table(df,index='cumcount',
columns='Info',
values='Values',
aggfunc='first' ).reset_index()[['ID','State','Address','Name']].\
fillna('').\
rename_axis(None, axis=1)
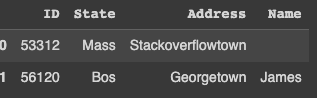
Output:
CodePudding user response:
The only way to achieve this is if you are certain that the ID row comes before all of the other info for that ID.
If you do have this assurance, the following will work, where df is the original DataFrame in your post:
ids = df.query("Info == 'ID'")['Values']
ids.name = 'ID'
df = df.join(ids)
df['ID'] = df['ID'].ffill()
df.query("Info != 'ID'", inplace=True)
res = df.pivot('ID', 'Info', 'Values')
Output of res: