I have a clustering problem in which I have to split a set S of samples into C clusters where C is known. Normally, I am able to perform the clustering operation with a simple KMeans clustering, which works just fine.
To complicate things, I have a known set of pairs D of samples that cannot under any circumstances be assinged to the same cluster. Currently I am not using this information and the clustering still works fine, but I would like to introduce it to improve robustness, since it comes for free from the problem I am trying to solve.
Example: S consists of 20 samples with 5 features each, C is 3, and D forces the following pairs {(1, 3), (3, 5), (10, 19)} to be in different clusters.
I am looking for a solution in python3, preferably with numpy/sklearn/scipy. Do you know if there is some out-of-the-box clustering algorithm that takes into account this kind of constraint? I have looked into sklearn but found no such thing.
CodePudding user response:
This sounds exactly like semi-supervised 
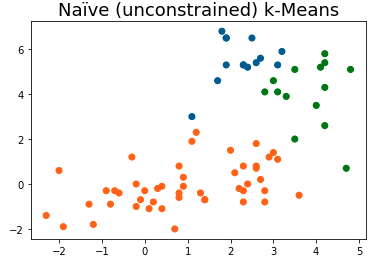
# Naïve Clustering
clust = PCKMeans(n_clusters=C, max_iter=1000)
clust.fit(S, cl=[], ml=[])
plt.title('Naïve (unconstrained) k-Means', fontsize=18)
plt.scatter(x=[s[0] for s in list(S)], y=[s[1] for s in list(S)], c=[colDict[c] for c in clust.labels_])
plt.show()
# Constr. Clustering
const_clust = PCKMeans(n_clusters=C, max_iter=10000)
const_clust.fit(S, ml=[], cl=D)
plt.title('Constrained k-Means', fontsize=18)
plt.scatter(x=[s[0] for s in S.tolist()], y=[s[1] for s in S.tolist()], c=[colDict[c] for c in const_clust.labels_])
plt.show()
which yields
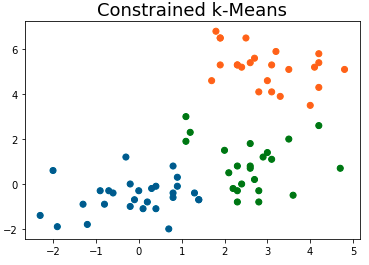
Although the plot looks different, checking if the cannot link-constraints are indeed met results in
[const_clust.labels_[d[0]] != const_clust.labels_[d[1]] for d in D]
>[True, False, True]
indicating that points with index 3 and 5 were assigned the same cluster label. Not good. However, the sample size and the distribution of the data points across the feature space seem to impact this greatly. Potentially, you will see no adverse effects when you apply it to your actual data.
Unfortunately, the repository does not allow to set a seed (to make the iterative estimation procedure reproducible) and ignores the one set via np.random.seed(567). Beware of reproducibility and rerun the code several times.
Other repositories such as scikit-learn indicate that some clustering routines may allow constraints but don't indicate how this can be done.
Note that there are other variants of constrained k-means clustering of this, e.g. where the pairwise constraints are not certain (see this reference) or the number of data points per cluster is constrained (see this python library).