Let's say I have to following dataframe
dput(df)
structure(list(Date_time = structure(c(1641025800, 1641025800,
1641025800, 1641025800, 1641025800, 1641025800, 1641025800, 1641025800,
1641027600, 1641027600, 1641027600, 1641027600, 1641027600, 1641027600,
1641027600, 1641027600, 1641027600, 1641027600, 1641027600, 1641027600,
1641027600, 1651396800, 1651396800, 1651396800, 1651396800, 1651396800,
1651396800, 1651396800, 1651396800, 1651396800, 1651401000, 1651401000,
1651401000, 1651401000, 1651401000, 1669966200, 1669966200, 1669966200,
1669966200, 1669966200, 1669966200, 1669966200, 1669966200, 1669969800,
1669969800, 1669969800, 1669969800, 1669969800, 1669969800, 1669969800,
1669969800, 1669969800, 1669969800, 1669969800, 1669969800), class = c("POSIXct",
"POSIXt"), tzone = "Europe/London"), Category = c("heat", "heat",
"heat", "heat", "heat", "heat", "heat", "heat", "cold", "cold",
"cold", "cold", "cold", "cold", "cold", "medium", "medium", "medium",
"medium", "medium", "medium", "heat", "heat", "heat", "heat",
"cold", "cold", "cold", "cold", "cold", "cold", "cold", "medium",
"medium", "medium", "heat", "heat", "heat", "heat", "heat", "cold",
"cold", "cold", "cold", "cold", "cold", "cold", "medium", "medium",
"medium", "medium", "medium", "medium", "heat", "heat"), SubCat = c("r",
"r", "r", "r", "n", "n", "n", "r", "r", "r", "r", "n", "n", "n",
"n", "r", "r", "r", "n", "n", "n", "n", "n", "n", "r", "r", "r",
"r", "n", "n", "n", "n", "r", "r", "r", "r", "r", "r", "n", "n",
"n", "n", "n", "n", "r", "r", "r", "r", "n", "n", "r", "r", "r",
"n", "n"), Site = c("1a", "1a", "1a", "1a", "1a", "1a", "1a",
"1a", "1a", "1a", "1b", "1b", "1b", "1b", "1b", "1b", "1b", "1b",
"1b", "1b", "1b", "2c", "2c", "2c", "2c", "2c", "2c", "2c", "2c",
"2c", "2c", "2c", "2c", "2c", "2c", "7c", "7c", "7c", "7c", "7c",
"7c", "7c", "7c", "7c", "7c", "7c", "7c", "7c", "7c", "7c", "7c",
"7c", "7c", "7c", "7c")), row.names = c(NA, -55L), class = "data.frame")
>
I would to produce some plots of the cumalative sums of each Category, by date, subcategory( and maybe Site too, but not sure if that will make sense). Essentially sum the total of each category per day, then add that to the next day in the dataframes total and so on. So that I end with something like below that I can plot
Date Category Subcategory Count
1 01/01/2022 Heat r 5
2 01/01/2022 Cold r 6
3 01/01/2022 Medium r 9
4 01/01/2022 Heat n 3
5 01/01/2022 Cold n 6
6 01/01/2022 Medium n 10
7 05/01/2022 Heat r 3
8 05/01/2022 Cold r 6
9 05/01/2022 Medium r 9
10 05/01/2022 Heat n 4
11 05/01/2022 Cold n 8
12 05/01/2022 Medium n 12
13 12/01/2022 Heat r 3
14 12/01/2022 Cold r 6
15 12/01/2022 Medium r 10
16 12/01/2022 Heat n 3
17 12/01/2022 Cold n 3
18 12/01/2022 Medium n 5
CodePudding user response:
dplyr solution:
library(dplyr)
structure(list(Date_time = structure(c(1641025800, 1641025800,
1641025800, 1641025800, 1641025800, 1641025800, 1641025800, 1641025800,
1641027600, 1641027600, 1641027600, 1641027600, 1641027600, 1641027600,
1641027600, 1641027600, 1641027600, 1641027600, 1641027600, 1641027600,
1641027600, 1651396800, 1651396800, 1651396800, 1651396800, 1651396800,
1651396800, 1651396800, 1651396800, 1651396800, 1651401000, 1651401000,
1651401000, 1651401000, 1651401000, 1669966200, 1669966200, 1669966200,
1669966200, 1669966200, 1669966200, 1669966200, 1669966200, 1669969800,
1669969800, 1669969800, 1669969800, 1669969800, 1669969800, 1669969800,
1669969800, 1669969800, 1669969800, 1669969800, 1669969800), class = c("POSIXct",
"POSIXt"), tzone = "Europe/London"), Category = c("heat", "heat",
"heat", "heat", "heat", "heat", "heat", "heat", "cold", "cold",
"cold", "cold", "cold", "cold", "cold", "medium", "medium", "medium",
"medium", "medium", "medium", "heat", "heat", "heat", "heat",
"cold", "cold", "cold", "cold", "cold", "cold", "cold", "medium",
"medium", "medium", "heat", "heat", "heat", "heat", "heat", "cold",
"cold", "cold", "cold", "cold", "cold", "cold", "medium", "medium",
"medium", "medium", "medium", "medium", "heat", "heat"), SubCat = c("r",
"r", "r", "r", "n", "n", "n", "r", "r", "r", "r", "n", "n", "n",
"n", "r", "r", "r", "n", "n", "n", "n", "n", "n", "r", "r", "r",
"r", "n", "n", "n", "n", "r", "r", "r", "r", "r", "r", "n", "n",
"n", "n", "n", "n", "r", "r", "r", "r", "n", "n", "r", "r", "r",
"n", "n"), Site = c("1a", "1a", "1a", "1a", "1a", "1a", "1a",
"1a", "1a", "1a", "1b", "1b", "1b", "1b", "1b", "1b", "1b", "1b",
"1b", "1b", "1b", "2c", "2c", "2c", "2c", "2c", "2c", "2c", "2c",
"2c", "2c", "2c", "2c", "2c", "2c", "7c", "7c", "7c", "7c", "7c",
"7c", "7c", "7c", "7c", "7c", "7c", "7c", "7c", "7c", "7c", "7c",
"7c", "7c", "7c", "7c")), row.names = c(NA, -55L), class = "data.frame") %>%
select(-Site, Subcategory = SubCat) %>%
group_by_all() %>%
count(name = 'Count') %>%
arrange(Date_time) %>%
group_by(Category, Subcategory) %>%
mutate(
Count = cumsum(Count)
)
# A tibble: 20 x 4
# Groups: Category, Subcategory [6]
Date_time Category Subcategory Count
<dttm> <chr> <chr> <int>
1 2022-01-01 08:30:00 heat n 3
2 2022-01-01 08:30:00 heat r 5
3 2022-01-01 09:00:00 cold n 4
4 2022-01-01 09:00:00 cold r 3
5 2022-01-01 09:00:00 medium n 3
6 2022-01-01 09:00:00 medium r 3
7 2022-05-01 10:20:00 cold n 6
8 2022-05-01 10:20:00 cold r 6
9 2022-05-01 10:20:00 heat n 6
10 2022-05-01 10:20:00 heat r 6
11 2022-05-01 11:30:00 cold n 8
12 2022-05-01 11:30:00 medium r 6
13 2022-12-02 07:30:00 cold n 11
14 2022-12-02 07:30:00 heat n 8
15 2022-12-02 07:30:00 heat r 9
16 2022-12-02 08:30:00 cold n 12
17 2022-12-02 08:30:00 cold r 9
18 2022-12-02 08:30:00 heat n 10
19 2022-12-02 08:30:00 medium n 5
20 2022-12-02 08:30:00 medium r 10
CodePudding user response:
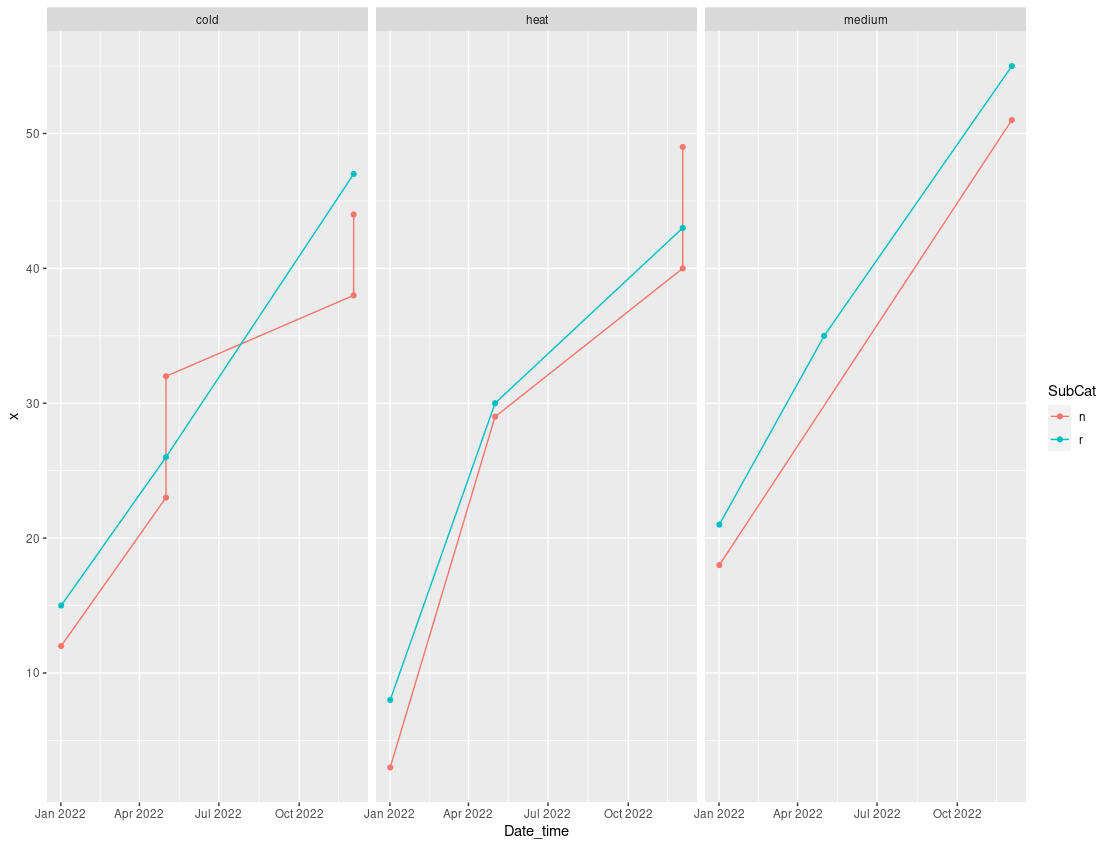
Something like this?
library(tidyverse)
df %>%
count(Date_time, Category, SubCat) %>%
mutate(x = cumsum(n)) %>%
ggplot(aes(x = Date_time, y=x, color=SubCat, group=SubCat))
geom_line()
geom_point()
facet_wrap(.~Category)