This is a followup question to 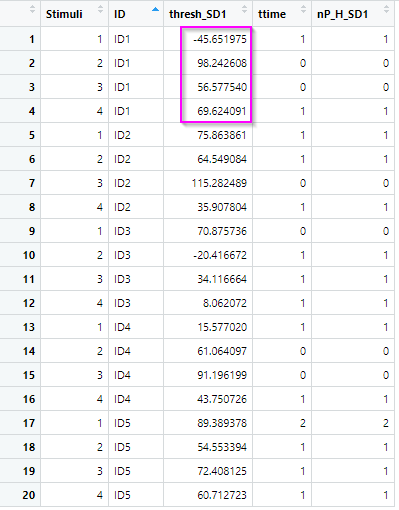
The problem with this output is that the thresholds for the same ID are different because the sd() was calculated per ID per Stimuli. I want to calculate the sd() across all Stimuli per ID and then count peaks per Stimuli. So, the output H_peaks_1_df here is perfect (group_by(Stimuli, ID)), just the column "thresh_SD1" should be the same value for ID1, namely "58.5" which is correctly calculated when grouping only by ID.

Is it possible in dplyr to execute the "thresh_SD1" calculation via group_by(ID) and then count peaks and total time via group_by(Stimuli, ID) in simple code?
Thanks in advance!
CodePudding user response:
Yes, it is possible, Using head, mean or other to retrieve only one element from thresh_SD1.
H_peaks_1_df <- DF %>% group_by(ID) %>%
mutate(thresh_SD1 = f.SD1(Happiness)) %>%
group_by(ID, Stimuli) %>%
summarise(thresh_SD1 = head(thresh_SD1,1), ttime = sum(Happiness > thresh_SD1), nP_H_SD1 = sum(diff(c(f.Peaks_SD1(Happiness, thresh = thresh_SD1), 0)) < 0))
H_peaks_1_df
ID Stimuli thresh_SD1 ttime nP_H_SD1
<chr> <int> <dbl> <int> <int>
1 ID1 1 58.5 0 0
2 ID1 2 58.5 2 2
3 ID1 3 58.5 0 0
4 ID1 4 58.5 1 1
5 ID2 1 71.3 1 1
6 ID2 2 71.3 1 1
7 ID2 3 71.3 3 1
8 ID2 4 71.3 0 0