I have a code that captures information and I need to transform the output of this information into a data frame using pytesseract and cv2
import pyautogui
import cv2
import pytesseract
import numpy as np
from PIL import ImageGrab, Image, ImageEnhance
import time
from pytesseract import Output
size = 1000, 1000
chats = []
pytesseract.pytesseract.tesseract_cmd
='My Patch to Tesseract'
def ScreenSearch():
while True:
time.sleep(1)
img = (ImageGrab.grab(bbox =(1290, 247, 1586, 517)))
img = img.resize(size, Image.ANTIALIAS)
gray = cv2.cvtColor(np.array(img), cv2.COLOR_BGR2GRAY)
# Perform text extraction
data = pytesseract.image_to_string(gray, lang='eng', config='--psm
6')
print(data)
print(type(data))
chats.append(data)
print(chats)
print(type(chats))
ScreenSearch()
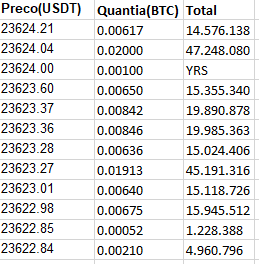
the outputs are in this format resulting in
Preco(USDT) Quantia(BTC) Total
23624.21 0.00617 145.76138
23624.04 0.02000 472.48080
23624.00 0.00100 YRS tt)
23623.60 0.00650 153.55340
23623.37 0.00842 198.90878
23623.36 0.00846 199.85363
23623.28 0.00636 150.24406
23623.27 0.01913 451.91316
23623.01 0.00640 151.18726
23622.98 0.00675 159.45512
23622.85 0.00052 12.28388
23622.84 0.00210 49.60796
<class 'str'>
['Preco(USDT) Quantia(BTC) Total\n23624.21 0.00617 145.76138\n23624.04 0.02000 472.48080\n23624.00 0.00100 YRS tt)\n23623.60 0.00650 153.55340\n23623.37 0.00842 198.90878\n23623.36 0.00846 199.85363\n23623.28 0.00636 150.24406\n23623.27 0.01913 451.91316\n23623.01 0.00640 151.18726\n23622.98 0.00675 159.45512\n23622.85 0.00052 12.28388\n23622.84 0.00210 49.60796\n']
<class 'list'>
How to transform one or both outputs into data frame?
CodePudding user response:
Use string.IO:
from io import StringIO
data = StringIO("""Preco(USDT) Quantia(BTC) Total
23624.21 0.00617 145.76138
23624.04 0.02000 472.48080
23624.00 0.00100 YRS
23623.60 0.00650 153.55340
23623.37 0.00842 198.90878
23623.36 0.00846 199.85363
23623.28 0.00636 150.24406
23623.27 0.01913 451.91316
23623.01 0.00640 151.18726
23622.98 0.00675 159.45512
23622.85 0.00052 12.28388
23622.84 0.00210 49.60796""".replace(' ', ','))
df = pd.read_csv(data)
Two things to note:
Since there is YRS instead of YRS tt in your desired output, I removed tt from the string. The second thing is you could directly use string.IO without needing replace but as your string has no seperator, I had to replace blanks with commas.
CodePudding user response:
Use pd.read_csv to convert the string to dataframe. You can use blank space as separator and add errors handle on lines with too much values (like 23624.00 0.00100 YRS tt)).
*sep=' ' can be replaced with delim_whitespace=True if you prefer
df = pd.read_csv(StringIO(data), sep=' ', on_bad_lines=lambda x: x[:3], engine='python')
print(df)
Output
Preco(USDT) Quantia(BTC) Total
0 23624.21 0.00617 145.76138
1 23624.04 0.02000 472.48080
2 23624.00 0.00100 YRS
3 23623.60 0.00650 153.55340
4 23623.37 0.00842 198.90878
5 23623.36 0.00846 199.85363
6 23623.28 0.00636 150.24406
7 23623.27 0.01913 451.91316
8 23623.01 0.00640 151.18726
9 23622.98 0.00675 159.45512
10 23622.85 0.00052 12.28388
11 23622.84 0.00210 49.60796