I'm working with a .csv dataset that I got from 
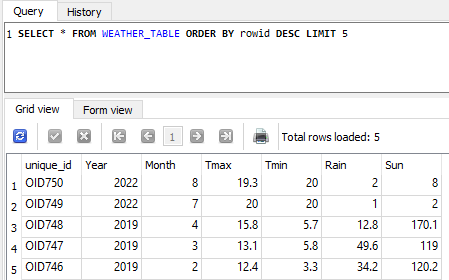
Also, whenever I update the dataframe (by adding some rows), these rows have to be inserted in the database/table with a unique ID (OIDx, with x as the row index in the table).
Is it possible to achieve this ? Do you have any propositions, please ?
CodePudding user response:
SQLite creates ROWID for you, unless you specifically instructed it not to do so.
CodePudding user response:
import sqlite3 as sql
import pandas as pd
weather = pd.read_csv("weather.csv", delimiter=",")
conn = sql.connect("weather.db")
weather["OID"] = list(map(lambda x: "OID" str(int(x)), weather.index))
print(weather.head())
output:
Year Month Tmax Tmin Rain Sun OID
0 1957 1 8.7 2.7 39.5 53.0 OID0
1 1957 2 9.0 2.9 69.8 64.9 OID1
2 1957 3 13.9 5.7 25.4 96.7 OID2
3 1957 4 14.2 5.2 5.7 169.6 OID3
4 1957 5 16.2 6.5 21.3 195.0 OID4
rest of the code:
schema = pd.io.json.build_table_schema(weather, primary_key="OID")
weather.to_sql("weather", conn, schema)
print(conn.execute("SELECT * FROM weather").fetchone())
output:
(0, 1957, 1, 8.7, 2.7, 39.5, 53.0, 'OID0')
If you want to add the OID to new rows execute this line again:
weather["OID"] = list(map(lambda x: "OID" str(int(x)), weather.index))
Just make sure you don't change the index of any of the rows
CodePudding user response:
After some digging and thanks to the SO posts/answers below, I managed to build the right code for my question :