I want to read Employee_detail_info file to azure databrikcs notebook from the blob storage container which contains other files also. The files will be loaded daily from source to blobstorage.
Employee_detail_Info_20220705000037
Customersdetais_info_20220625000038
allinvocie_details_20220620155736
CodePudding user response:
You can use Glob patterns to achieve the requirement. The following is the demonstration of the same.
- The following are the list of files in my storage account.
Customersdetais_info_20220625000038.csv
Employee_detail_Info_20220705000037.csv
Employee_detail_Info_20220822000037.csv
Employee_detail_Info_20220822000054.csv
allinvocie_details_20220620155736.csv
#all employee files have same schema and 1 row each for demo
- Now, create a pattern for your
employee_details_infotype files. I have useddatetimelibrary to achieve this. Since every employee file has today's date asyyyyMMdd, I have created a pattern indicating the same.
from datetime import datetime
todays_date = datetime.utcnow().strftime("%Y%m%d")
print(todays_date) #20220822
file_name_pattern = "Employee_detail_Info_" todays_date
print(file_name_pattern) #Employee_detail_Info_20220822
- Now you can use
Asterisk (*)glob pattern to read all the files that match ourfile_name_pattern.
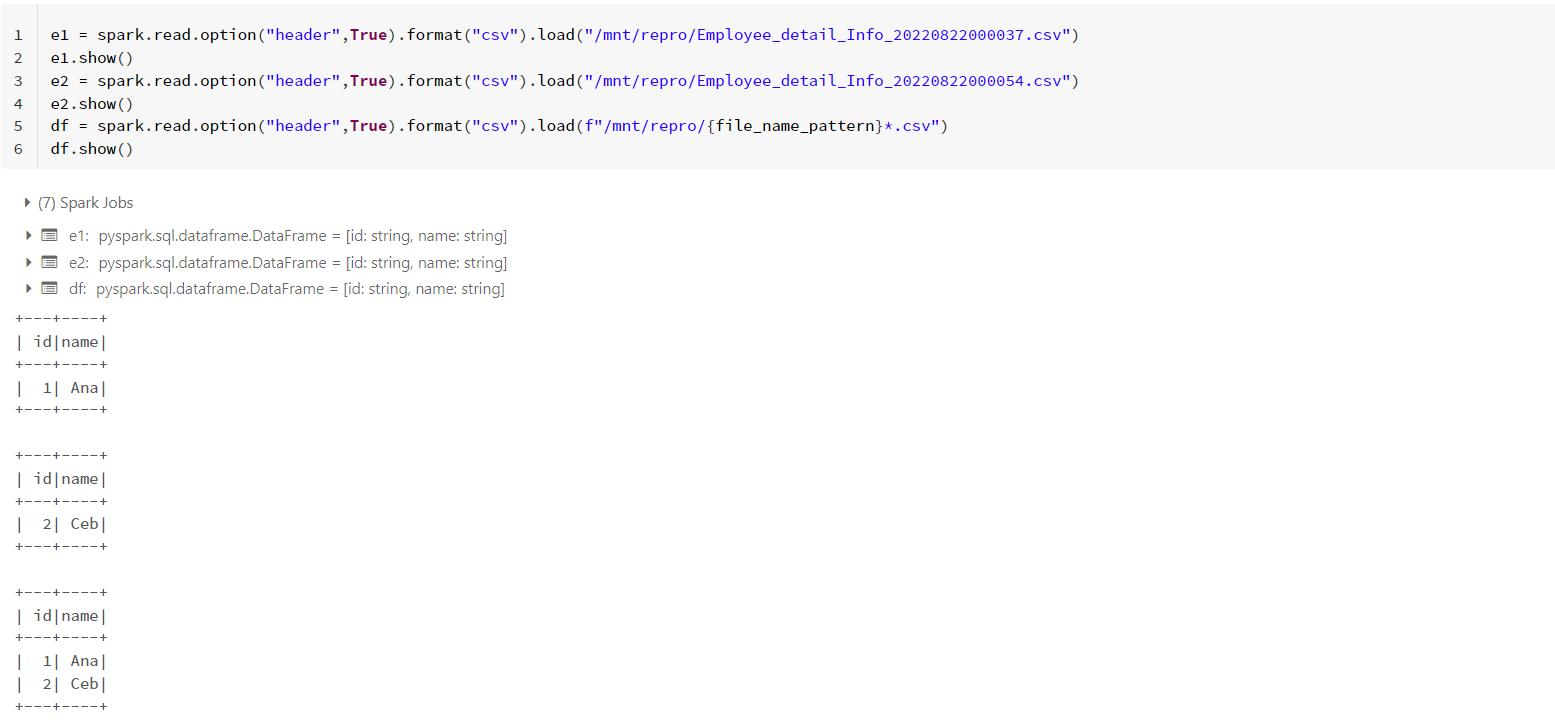
df = spark.read.option("header",True).format("csv").load(f"/mnt/repro/{file_name_pattern}*.csv")
#you can specify,required file format and change the above accordingly.
df.show()
The following are the images of my output for reference.
- My files:
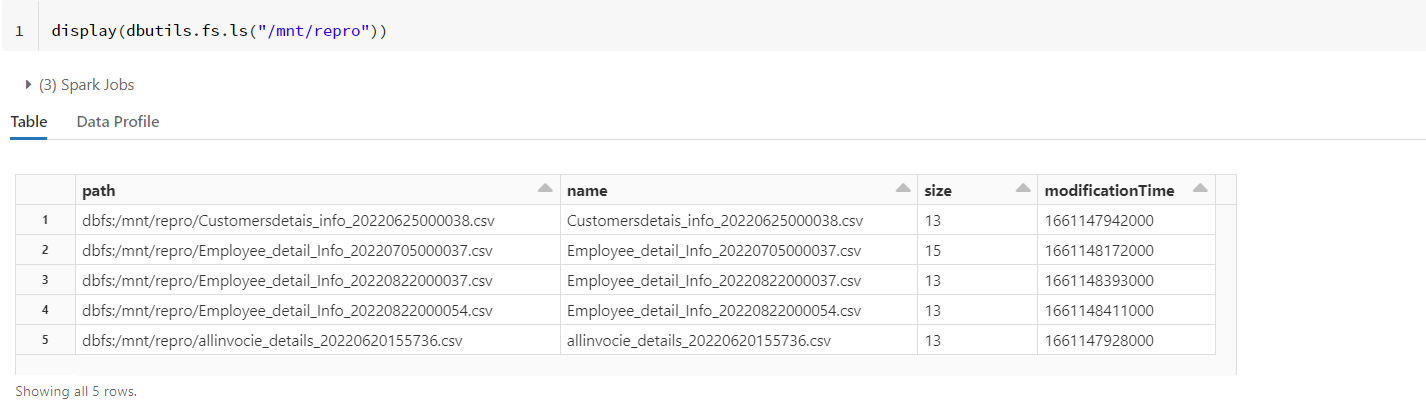
- Output: