In the following dataframe:
country admin_1 admin_2 year season_name production area
A1 B1 C1 1991 Primary 43170 25980
A1 B1 C1 1990 Primary 45624 29820
A1 B1 C1 1989 Primary 56310 31284
A1 B1 C1 1988 Primary 33523 24832
A1 B1 C1 1987 Primary 49388 33479
A1 B1 C1 1986 Primary 36475 27425
A1 B1 C1 1985 Primary 32278 32046
A1 B1 C1 1984 Primary 52073 28929
A1 B1 C1 1983 Primary 51746 32855
A1 B1 C2 1991 Primary 32010 20010
A1 B1 C2 1990 Primary 52704 19520
A1 B1 C2 1989 Primary 65240 18640
A1 B1 C2 1988 Primary 11570 17800
A1 B1 C2 1987 Primary 51282 20350
A1 B1 C2 1986 Primary 25808 19816
A1 B1 C2 1985 Primary 16935 18817
A1 B2 C3 1987 Primary 51282 20350
A1 B2 C3 1986 Primary 25808 19816
A1 B2 C3 1985 Primary 16935 18817
I want to determine the percentage of area for each admin_2 by averaging the area across all years for each admin_2 and them computing the percentage. This is what I tried:
df['area_percentage'] = df.groupby(['country', 'admin_2'])['area'].apply(lambda x: x / x.sum())
CodePudding user response:
Try:
df['area_percentage'] = df['area'] / df.groupby(['country', 'admin_2'])['area'].transform('sum') * 100
CodePudding user response:
Well, since the question is somewhat vague, I'll do a sort of mental exercise.
Let's see how we can interpret "the percentage of area for each admin_2 by averaging the area across all years for each admin_2".
Looking at the first attempt, which is considered wrong, I could come up with something like this:
s = df.groupby(['country', 'admin_2'])['area'].mean()
s /= s.sum()
Output:
country admin_2
A1 C1 0.432095
C2 0.281167
C3 0.286738
But it looks weird. What could be the benefit of normalizing means? I don't know. So let's skip it and do something different.
What if we sum up the area for all the years grouped by admini_2 and divide the result by the total area?
s = df.groupby(['country', 'admin_2'])['area'].sum()
s /= s.sum()
Output:
country admin_2
A1 C1 0.578936
C2 0.293003
C3 0.128061
Well, it might work if the nature of area implies the accumulation. In this case, we can talk about the overall percentage of area for each admin_2.
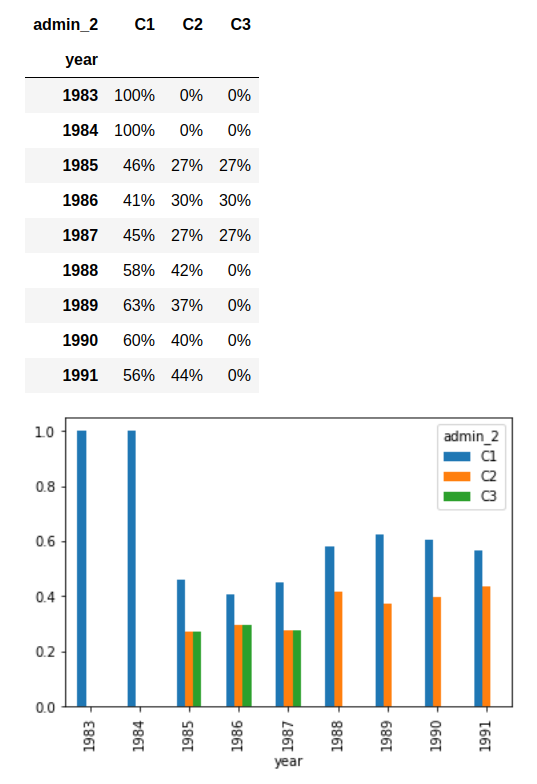
But what if there's no "accumulation" on the table? Let's say the area means the amount of work that must be done when necessary during the year. In this case we could interpret the request this way: compare area for each admin_2 by year. From the data presented I might conclude that country and admin_1 do not really matter. They are the same for each admin_2, so I guess they can be ignored (otherwise, we simply add them to the pivot table index). In this case, I'd do something like this:
_df = df.pivot('admin_2','year','area')
_df = (_df / _df.sum()).T
display(_df.fillna(0).style.format('{0:.0%}'.format))
_df.plot(kind='bar'))
Output: