I have 4 datasets:
df1 <- data.frame(value_1 = c(1,2,3,4), row.names = c("A", "B", "C", "D"))
df2 <- data.frame(value_2 = c(1,2,3,4,5), row.names = c("A", "B", "C", "D", "E"))
df3 <- data.frame(value_3 = c(1,2,3), row.names = c("A", "D", "E"))
df4 <- data.frame(value_4 = c(5, 6, 7, 8), row.names = c("A", "C", "D", "E"))
I need to have this output:
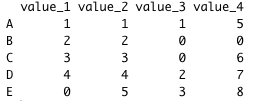
I found some similar questions, but they do not work in my case.
this:
do.call("merge", c(lapply(list(df1, df2, df3, df4), data.frame, row.names=NULL),
by = 0, all = TRUE))
gives an error
Error in fix.by(by.x, x) : 'by' must specify one or more columns as numbers, names or logical
this
Reduce(function(x, y) merge(x, y, all=TRUE), list(df1, df2, df3, df4))
duplicates values
CodePudding user response:
We may create a row names column in the data and use that for joining
library(dplyr)
library(tibble)
library(purrr)
library(tidyr)
list(df1, df2, df3, df4) %>%
map(~ .x %>% rownames_to_column('rn')) %>%
reduce(full_join, by = "rn") %>%
mutate(across(-rn, replace_na, 0)) %>%
column_to_rownames('rn')
-output
value_1 value_2 value_3 value_4
A 1 1 1 5
B 2 2 0 0
C 3 3 0 6
D 4 4 2 7
E 0 5 3 8
The by = 0 or by = "row.names" works for the first join, but after the first merge, row.name will be a column
> merge(df1, df2, by = "row.names", all = TRUE)
Row.names value_1 value_2
1 A 1 1
2 B 2 2
3 C 3 3
4 D 4 4
5 E NA 5
and thus it wouldn't work. We could create a column and then do the merge
Reduce(\(x, y) merge(x, y, by = 'rn', all = TRUE),
lapply(list(df1, df2, df3, df4), \(x) transform(x,
rn = row.names(x))))
rn value_1 value_2 value_3 value_4
1 A 1 1 1 5
2 B 2 2 NA NA
3 C 3 3 NA 6
4 D 4 4 2 7
5 E NA 5 3 8
Or in a base R |>
list(df1, df2, df3, df4) |>
lapply(\(x) transform(x, rn = row.names(x))) |>
Reduce(\(x, y) merge(x, y, all = TRUE), x = _)
rn value_1 value_2 value_3 value_4
1 A 1 1 1 5
2 B 2 2 NA NA
3 C 3 3 NA 6
4 D 4 4 2 7
5 E NA 5 3 8
Or another option would be to do a join first between the first two datasets, keep it in a list, and then use by.x and by.y
list(merge(df1, df2, by = "row.names", all = TRUE), df3, df4) |>
Reduce(\(x, y) merge(x, y, by.x = "Row.names",
by.y = "row.names", all = TRUE), x = _)
Row.names value_1 value_2 value_3 value_4
1 A 1 1 1 5
2 B 2 2 NA NA
3 C 3 3 NA 6
4 D 4 4 2 7
5 E NA 5 3 8
If we don't want to do the first two dataset join separately, then create a function to dynamically check if the "Row.name" column exist or not, and make changes to by.x and by.y accordingly
f1 <- function(x, y)
{
i1 <- any(grepl("Row.names", names(x)))
i2 <- any(grepl("Row.names", names(y)))
nm1 <- if(i1) "Row.names"else "row.names"
nm2 <- if(i2) "Row.names" else "row.names"
merge(x, y, by.x = nm1, by.y = nm2 , all = TRUE)
}
list(df1, df2, df3, df4) |>
Reduce(f1, x= _)
Row.names value_1 value_2 value_3 value_4
1 A 1 1 1 5
2 B 2 2 NA NA
3 C 3 3 NA 6
4 D 4 4 2 7
5 E NA 5 3 8
CodePudding user response:
A data.table approach:
library(data.table)
Reduce(function(x, y) merge(x, y, all = TRUE),
lapply(list(df1, df2, df3, df4), function(y) data.table(y, keep.rownames=TRUE, key = "rn")))
rn value_1 value_2 value_3 value_4
1: A 1 1 1 5
2: B 2 2 NA NA
3: C 3 3 NA 6
4: D 4 4 2 7
5: E NA 5 3 8