New to python. I need to merge CA1 with CA2 and CB1 with CB2 and re-arrange the data with a specific order shown in the example. Dataset
| CA1 | CB1 | CA2 | CB2 | |
|---|---|---|---|---|
| 1 | A | 1.1 | B | 1.2 |
| 2 | C | 1.3 | D | 1.4 |
| 3 | E | 1.5 | F | 1.6 |
| 4 | G | 1.7 | H | 1.8 |
Needed as
| CA1 | CB1 | |
|---|---|---|
| 1 | A | 1.1 |
| 2 | B | 1.2 |
| 3 | C | 1.3 |
| 4 | D | 1.4 |
| 5 | E | 1.5 |
| 6 | F | 1.6 |
| 7 | G | 1.7 |
| 8 | H | 1.8 |
CodePudding user response:
Just stack the column pairs and create DataFrame out of them:
>>> pd.DataFrame({'CA1': df[['CA1', 'CA2']].stack().values,
'CB1': df[['CB1', 'CB2']].stack().values})
CA1 CB1
0 A 1.1
1 B 1.2
2 C 1.3
3 D 1.4
4 E 1.5
5 F 1.6
6 G 1.7
7 H 1.8
CodePudding user response:
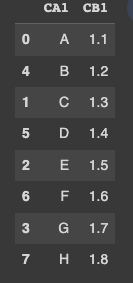
Check Below Code using - Numpy
import pandas as pd
import numpy as np
df = pd.DataFrame({'CA1':['A','C','E','G'],'CB1':[1.1,1.3,1.5,1.7],'CA2':['B','D','F','H'], 'CB2':[1.2,1.4,1.6,1.8]})
pd.DataFrame(np.vstack([df[['CA1','CB1']].values,df[['CA2','CB2']].values]), columns=['CA1','CB1']).sort_values('CA1')
Output:
CodePudding user response:
Split your dataframe into 2 parts, and concatenate them vertically. Then sort columns individually:
first = df[['CA1', 'CB1']]
second = df[['CA2', 'CB2']].set_axis(['CA1', 'CB1'], axis=1)
result = pd.concat([first, second], axis=0, ignore_index=True)
for col in result:
result[col] = result[col].sort_values(ignore_index=True)
Result:
CA1 CB1
0 A 1.1
1 B 1.2
2 C 1.3
3 D 1.4
4 E 1.5
5 F 1.6
6 G 1.7
7 H 1.8
CodePudding user response:
One option is with pivot_longer from pyjanitor:
# pip install pyjanitor
import pandas as pd
import janitor
df.pivot_longer(
index = None,
names_to = ('CA1', 'CB1'),
names_pattern = ['CA', 'CB'],
sort_by_appearance=True)
CA1 CB1
0 A 1.1
1 B 1.2
2 C 1.3
3 D 1.4
4 E 1.5
5 F 1.6
6 G 1.7
7 H 1.8
CodePudding user response:
### Assuming your dataframe is called df
df = pd.DataFrame.from_records([{
'CA1': 'A', 'CB1': 1.1, 'CA2': 'B', 'CB2': 1.2},
{'CA1': 'C', 'CB1': 1.3, 'CA2': 'D', 'CB2': 1.4},
{'CA1': 'E', 'CB1': 1.5, 'CA2': 'F', 'CB2': 1.6},
{'CA1': 'G', 'CB1': 1.7, 'CA2': 'H', 'CB2': 1.8}])
# Make new dataframe with extra columns and rename the headers to match
df2 = df[['CA2', 'CB2']].rename(columns={
'CA2': 'CA1', 'CB2': 'CB1'}
)
# Drop the extra columns from your initial dataframe
df.drop(columns=['CA2','CB2'], inplace=True)
# Concat the dataframes
# ignore index so your index continues naturally rather than resetting
df = pd.concat([df, df2], ignore_index=True)
### Sort your dataframe by CA1 first, then CB1
df.sort_values(by=['CA1', 'CB1'], inplace=True, ignore_index=True)
print(df)