I have the dataframe below.
import pandas as pd
import numpy as np
# data stored in dictionary
details = {
'address_id': [111,111,111,111,111,111,222,222,222,222,222,222,333,333,333,333,333,333,444,444,444,444,444,444,555,555,555,555,555,555,777,777,777],
'my_company':['Comcast','Verizon','Other','Other','Comcast','Comcast','Spectrum','Spectrum','Spectrum','Spectrum','Spectrum','Spectrum','Verizon','Verizon','Verizon','Verizon','Verizon','Verizon','Spectrum','Spectrum','Spectrum','Spectrum','Verizon','Spectrum','Spectrum','Spectrum','Spectrum','Spectrum','Verizon','Other','Verizon','Comcast','Comcast'],
'my_date':['2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28','2022-04-25','2022-05-23','2022-06-27','2022-01-24','2022-02-21','2022-03-28']
}
df = pd.DataFrame(details)
df
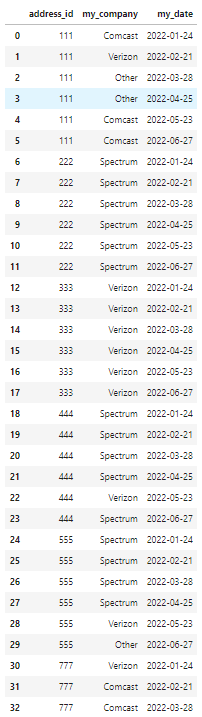
I want to see if an address_id switched AWAY from Verizon at some point during various durations of time, but grouped by address_id. If an address_id has Verizon in an earlier month, and switch to something else at any point later in time, I want to label it as a mover=TRUE.
- If the house never had Verizon, then mover = False
- If the house did not start with Verizon but ended with Verizon, then mover = False
- If the house had Verizon at some point, but did not end with Verizon, then mover = True
I want to end up with this.
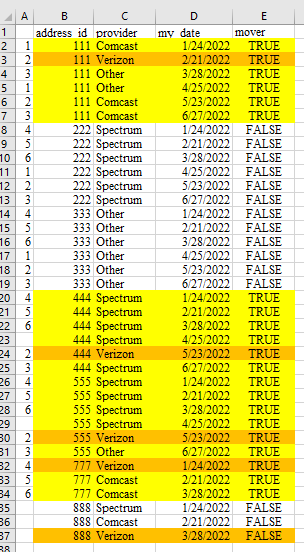
How can I do that?
So, I tried this...I think it's close...
df['mover'] = df.address_id.map(df.groupby(['address_id'])['my_date']=descending).last().my_company) == 'Verizon'
df
I'm seeing: SyntaxError: invalid syntax
CodePudding user response:
def f(ser):
if 'Verizon' not in ser.unique():
return False
if ser.iloc[-1] == 'Verizon':
return False
return True
df['mover'] = df.groupby('address_id')['my_company'].transform(f)
Result:
address_id my_company my_date mover
0 111 Comcast 2022-01-24 True
1 111 Verizon 2022-02-21 True
2 111 Other 2022-03-28 True
3 111 Other 2022-04-25 True
4 111 Comcast 2022-05-23 True
5 111 Comcast 2022-06-27 True
6 222 Spectrum 2022-01-24 False
7 222 Spectrum 2022-02-21 False
8 222 Spectrum 2022-03-28 False
9 222 Spectrum 2022-04-25 False
10 222 Spectrum 2022-05-23 False
11 222 Spectrum 2022-06-27 False
12 333 Verizon 2022-01-24 False
13 333 Verizon 2022-02-21 False
14 333 Verizon 2022-03-28 False
15 333 Verizon 2022-04-25 False
16 333 Verizon 2022-05-23 False
17 333 Verizon 2022-06-27 False
18 444 Spectrum 2022-01-24 True
19 444 Spectrum 2022-02-21 True
20 444 Spectrum 2022-03-28 True
21 444 Spectrum 2022-04-25 True
22 444 Verizon 2022-05-23 True
23 444 Spectrum 2022-06-27 True
24 555 Spectrum 2022-01-24 True
25 555 Spectrum 2022-02-21 True
26 555 Spectrum 2022-03-28 True
27 555 Spectrum 2022-04-25 True
28 555 Verizon 2022-05-23 True
29 555 Other 2022-06-27 True
30 777 Verizon 2022-01-24 True
31 777 Comcast 2022-02-21 True
32 777 Comcast 2022-03-28 True
33 888 Spectrum 2022-01-24 False
34 888 Comcast 2022-02-21 False
35 888 Verizon 2022-03-28 False