I need to filter or delete values and my code take long time. And also, these are very small files because I will run same process on bigger files. I have Windows pro, Xeon, 64 RAM, SDD but only use 4%. So how I can improve? Maybe with numpy, pandas or async, multiprocessing and multithreading?
df = pd.read_csv('rent3_dupli_mayor_0.csv', sep = ',', dtype='unicode', low_memory=False)
dfr_3 = pd.read_csv('renta3_3_1.csv', sep = ',', dtype='unicode', low_memory=False)
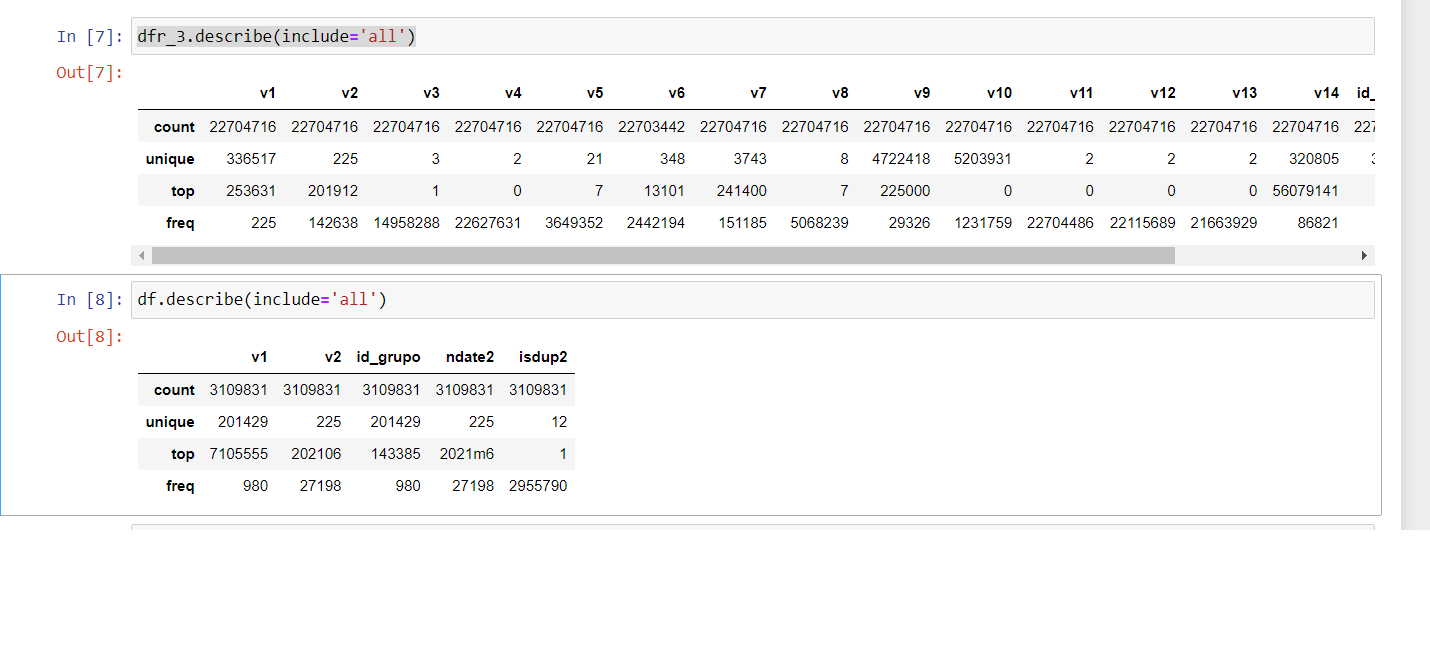
dfr_3.describe(include='all')
df.describe(include='all')
list_3_1=pd.unique(df['v1']).tolist()
for ddel1 in list_3_1:
dfr_3 = dfr_3[dfr_3.v1 != ddel1]
Maybe a for loop is wrong way. Looping taking too much time.
How I can improve my code? I am trying to delete all numbers of my list (unique values: 201429) that I can find in my dataframe. If you can see my dataframe has 22704716 (line of values).
CodePudding user response:
I don't know if your dfs are patched constantly and have increasing amounts of data. But something I would recommend to you is, to instead of using csv files, use feather files.
About your little code there is ways of going about it, I think the most efficient would be to construct a map. Based on your unique Ids, but I doubt that factor will be the "real" bother.
dfr_3 = dfr_3[~dfr_3.v1.isin(list_3_1)]
Here are the docs for feathers files
https://arrow.apache.org/docs/python/generated/pyarrow.feather.write_feather.html
CodePudding user response:
You can try this:
dfr_3 = dfr_3[~dfr_3.v1.isin(list_3_1)]