I'm trying to build a sheet whereby I have a new column ('column x').
This column would be populated by scanning over three already existing columns (a, b , c).
if a given value is found in any of those columns for the indexed figure the new column will read 'Fail' else it will read 'pass.
When i try this on scanning a single column my code works
example:
df["Column x"] = df["Column a"].apply(lambda val: "Fail" if val == 'T' else "Pass")
When i try in more than one it fails no matter how i adjust.
df['Column x'] = df['Column a'].any(lambda val: 'Fail' if val == 0 else 'Pass') or df['Column b'].apply(lambda val: 'Fail' if val == 'False' else 'Pass')
any advise is incredibly helpful
CodePudding user response:
Check Below code with np.where, checking for J if present in any column than False else True
import pandas as pd
import numpy as np
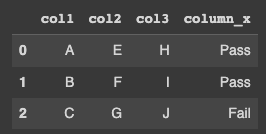
df = pd.DataFrame({'col1':['A','B','C'],'col2':['E','F','G'],'col3':['H','I','J']})
df['column_x'] = np.where(((df['col1']=='J')|(df['col2']=='J')|(df['col3']=='J')),'Fail','Pass')
df
Output:
CodePudding user response:
Here is an all pandas code:
import pandas as pd
df = pd.DataFrame({
'col1':['A','B','C'],
'col2':['E','F','G'],
'col3':['H','I','J']}
)
df["C"] = pd.Series(
df['col1'].apply(lambda a: 0 if a == 'C' else 1) &
df['col2'].apply(lambda a: 0 if a == 'C' else 1) &
df['col3'].apply(lambda a: 0 if a == 'C' else 1)
).apply(lambda x: "Pass" if x else 'Fail')
print(df)
output
col1 col2 col3 C
0 A E H Pass
1 B F I Pass
2 C G J Fail