Input is
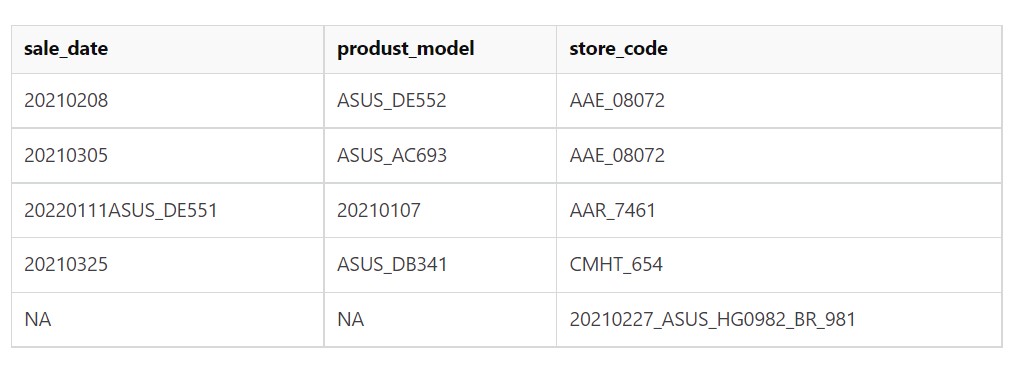
the row 3 and row 5 had incorrtct format, if I want
| sale_date | produst_model | store_code |
|---|---|---|
| 20210208 | ASUS_DE552 | AAE_08072 |
| 20210305 | ASUS_AC693 | AAE_08072 |
| 20210107 | ASUS_DE551 | AAR_7461 |
| 20210325 | ASUS_DB341 | CMHT_654 |
| 20210227 | ASUS_HG0982 | BR_981 |
If this table have 20,000 rows, Do I have more efficiency way to check every row is match rule?
CodePudding user response:
From looking at the data posted my hunch is that the strings in the three columns were at some point extracted from a composite string such as 20210227_ASUS_HG0982_BR_981 but the extraction seems to have gone wrong in some places. If this assumption is correct then I would recommend going back to the original strings and fixing the extraction, for example like this using the extract function:
library(tidyverse)
data.frame(original) %>%
extract(original,
into = c("sale_date", "produst_model", "store_code"),
regex = "(\\d )_(\\w \\d )_(\\w )")
sale_date produst_model store_code
1 20210227 ASUS_HG0982 BR_981
Data:
original = "20210227_ASUS_HG0982_BR_981"
Obviously, the regex here is based only on a single string and will likely have to be adapted as soon as you have more strings.