I would like to scrape all the statistics in the page
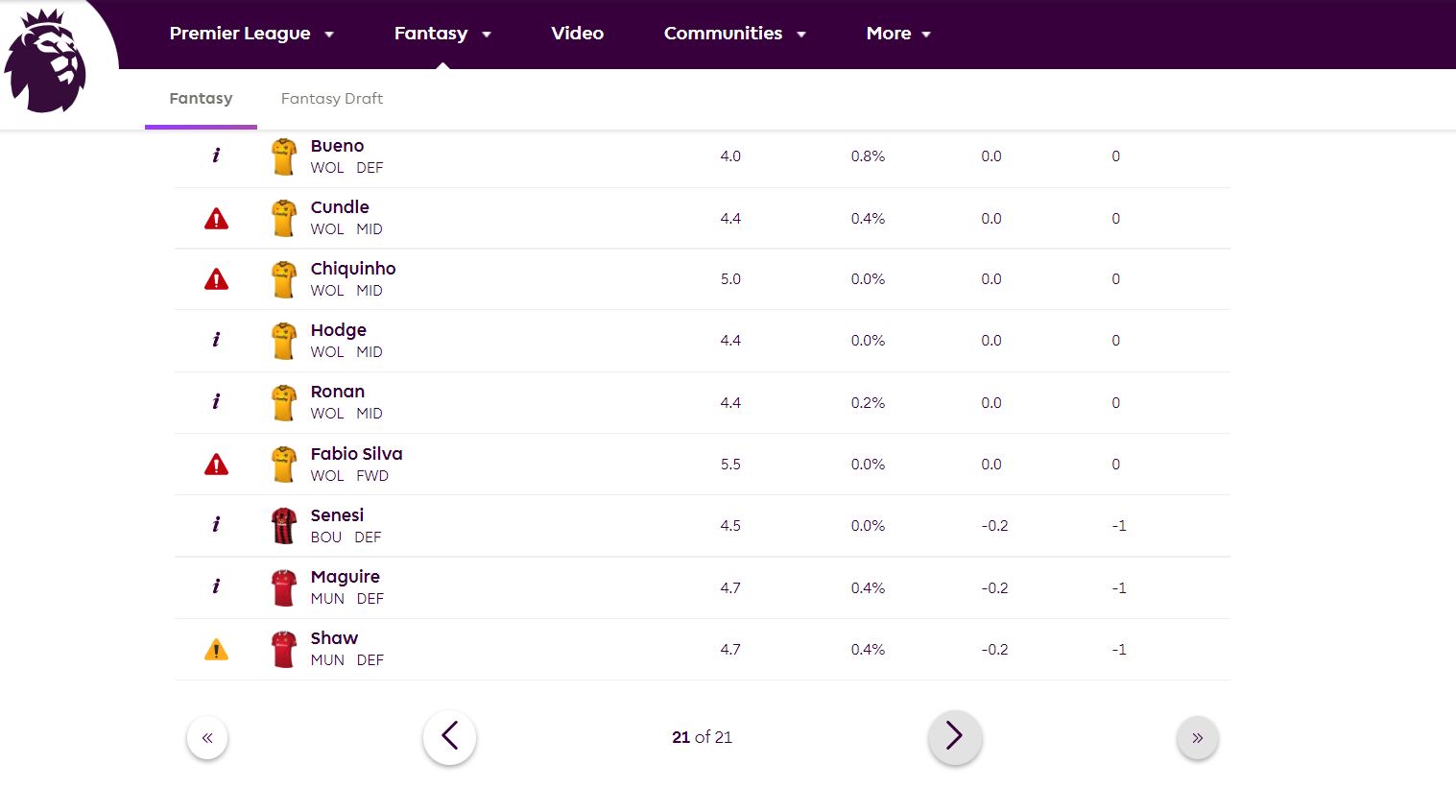
whereas my parquet file returns the results on the first page.
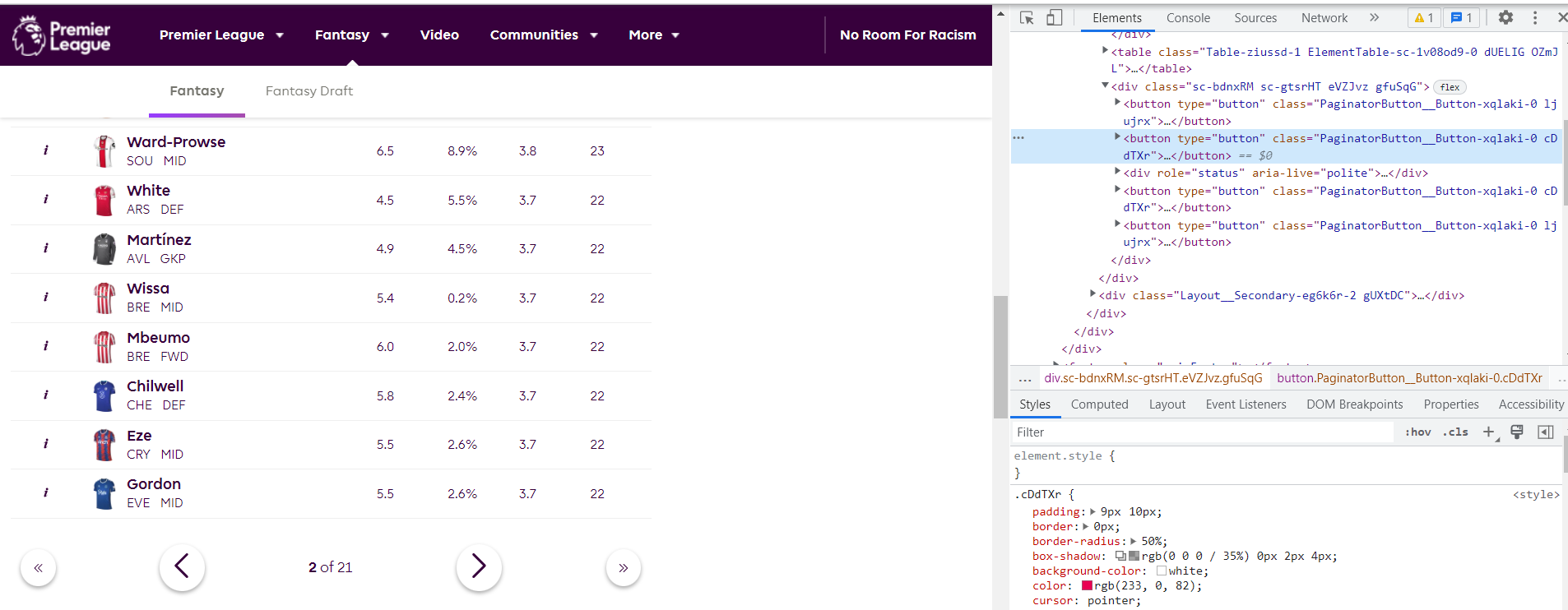
Both the previous and next buttons have the same CSS selectors.
CodePudding user response:
In this command try changing from wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="root"]/div[2]/div/div[1]/div[3]/button[3]/svg'))).click() to
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button svg[class*='ChevronRight']"))).click()
Also make sure you are scrolling to the bottom so this element becomes clickable
CodePudding user response:
You surely must have a reason to use selenium.. but just in case, here is a less overhead..ish solution, avoiding Selenium:
import requests
import pandas as pd
url = 'https://fantasy.premierleague.com/api/bootstrap-static/'
r = requests.get(url)
df = pd.DataFrame(r.json()['elements'])
df.sort_values(by=['total_points'], inplace=True, ascending=False)
print(df[['web_name', 'now_cost', 'form', 'total_points']])
Result:
web_name now_cost form total_points
393 Haaland 119 11.2 67
91 Toney 71 7.5 45
538 Kane 114 6.7 40
259 Mitrović 68 6.5 39
314 Rodrigo 64 6.3 38
... ... ... ... ...
243 Garner 45 0.0 0
0 Cédric 42 0.0 0
86 Senesi 45 -0.2 -1
412 Shaw 47 -0.2 -1
410 Maguire 47 -0.2 -1
624 rows × 4 columns
Data in that webpage is being pulled dynamically from an API endpoint. This is visible in Dev tools - Network tab. By scraping that endpoint, you get a fairly large JSON object, which you can dissect and extract the visible table in page, and also other stuffs, if you are so inclined (just inspect it).
This is python Requests documentation: https://requests.readthedocs.io/en/latest/