I am currently working on an Inventory System, and have just developed code that allows me to add items to my .csv
My current csv file looks like this:
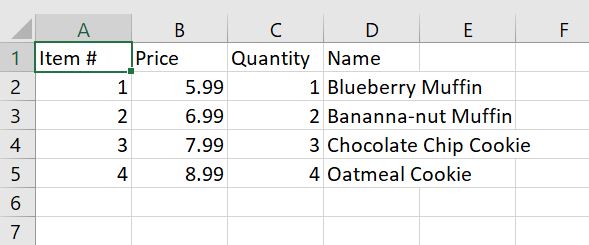
Here is my relevant code:
class CsvReader:
def __init__(self):
self.result = []
def make_dict_items(self):
#fn = os.path.join('subdir', "Items2.csv")
with open("Items2.csv") as fp:
reader = csv.reader(fp)
labels = next(reader, None)
result = []
for row in reader:
row[0] = int(row[0])
row[1] = float(row[1])
row[2] = int(row[2])
pairs = zip(labels, row)
self.result.append(dict(pairs))
def show_available(self):
for item in self.result:
print(item)
def add_item(self):
item_num = int(input("What is the items #?\n"))
price = float(input("What is the items price?\n"))
quant = int(input("What is the items quantity?\n"))
name = input("What is the items name?\n")
new_row = [item_num, price, quant, name]
with open("Items2.csv", "a ") as fp:
reader = csv.reader(fp)
fp.seek(0)
labels = next(reader, None)
writer = csv.writer(fp)
new_record = dict(zip(labels, new_row))
self.result.append(new_record)
writer.writerow(new_record.values())
From what I understand, my add item is able to successfully input into my csv. For example, if I input 1, 2.99, 3, and Pumpkin into the inputs, and print(system.result), I can see the new dictionary in the list, and visually see it if I were to open the csv document.
What I dont understand is my current error I am getting. When I try to view my new item with my existing method that shows all items, I get an error:
row[0] = int(row[0])
IndexError: list index out of range
I understand this error has to do with trying to call elements in a list that don't exist, but what seems to be the issue here. Why when I have the four items in my csv, the code works fine, but when I add a new row into the csv file, the code fails? Why does that specific line in make_dict_items not work when a 5th item is added, but works with the beginning four?
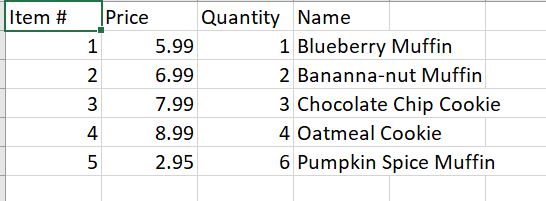
CodePudding user response:
Your CSV has blank lines, which create empty row. Check for this and skip it.
for row in reader:
if row:
row[0] = int(row[0])
row[1] = float(row[1])
row[2] = int(row[2])
pairs = zip(labels, row)
self.result.append(dict(pairs))
CodePudding user response:
I would also suggest looking into something like dataclasses and dataclass-csv for this, just to align with best practices in Python and to also to streamline the task, and make it easier to work with the data.
For example, here's a working sample I was able to test with. This works with pip install dataclass-csv to install the library beforehand.
from dataclasses import dataclass
import dataclass_csv
@dataclass
class MyClass:
item_no: int
price: float
quantity: int
name: str
with open('Book.csv') as f:
reader = dataclass_csv.DataclassReader(f, MyClass)
reader.map('Item #').to('item_no')
reader.map('Price').to('price')
reader.map('Name').to('name')
reader.map('Quantity').to('quantity')
for line in reader:
print(line)
Notice here how the type annotations such as price: float indicate that the type of the field should be float for example.
The output of the above code is as follows:
MyClass(item_no=1, price=5.99, quantity=1, name='Blueberry Muffin')
MyClass(item_no=2, price=6.99, quantity=2, name='Bannana-nut Muffin')
MyClass(item_no=3, price=7.99, quantity=3, name='Chocolate Chip Cookie')
MyClass(item_no=4, price=8.99, quantity=4, name='Oatmeal Cookie')