I have data from survey that comes with typos, missing data and others. I need to populate/clean data within groups, considering that if there is any valid value (making sure there is just one valid value) for the variable within the group, it should replace the other values in variable in same group. See below my mock data and the result expected. I am being reading about fill, mutate using group_by but still have no idea on how to do it.
Idea: if value is not in ("Unknown", "NA, "N/A", "null"), then copy that value in the variable within the group
Data:
data <- data.frame(group = c("A1", "A1", "A1", "A1", "A2", "A2", "B4", "B4", "B4", "C1"),
number.persons = c("4",NA,NA, "N/A", "unknow", "2", "3", "3", NA,"1"),
own.rent = c("own", "own", NA, "N/A", "rent", NA, "own", "N/A", "own", "own"),
car =c("yes", "yes", NA, "unkwon", "no", NA, "no", "no", "unknwon", "no"))

Desired result:
new.data <- data.frame(group = c("A1", "A1", "A1", "A1", "A2", "A2", "B4", "B4", "B4", "C1"),
number.persons = c("4","4","4", "4", "2", "2", "3", "3", "3","1"),
own.rent = c("own", "own", "own", "own", "rent", "rent", "own", "own", "own", "own"),
car =c("yes", "yes", "yes", "yes", "no", "no", "no", "no", "no", "no"))

One solution I came up:
data.pre <- data %>%
mutate(flag.number.persons = ifelse(!number.persons %in% c("unknow", "unkwon","unknwon","null", "na", "n/a", "N/A", "NA", "") & !is.na(number.persons), 1, 0),
flag.own.rent = ifelse(!own.rent %in% c("unknow", "unkwon","null", "unknwon","na", "n/a", "N/A", "NA", "") & !is.na(own.rent), 1, 0),
flag.car = ifelse(!car %in% c("unknow", "unkwon","null", "unknwon","na", "n/a", "N/A", "NA", "") & !is.na(car), 1, 0)) %>%
group_by(group) %>%
mutate(number.persons2 = ifelse(flag.number.persons==0, number.persons[flag.number.persons==1], number.persons),
own.rent2 = ifelse(flag.own.rent == 0, own.rent[flag.own.rent==1], own.rent),
car2 = ifelse(flag.car == 0 , car[flag.car==1], car))
Looking at the new data with new variables to see how it worked my code:
subset(data.pre, select=c(group, number.persons2, own.rent2, car2))
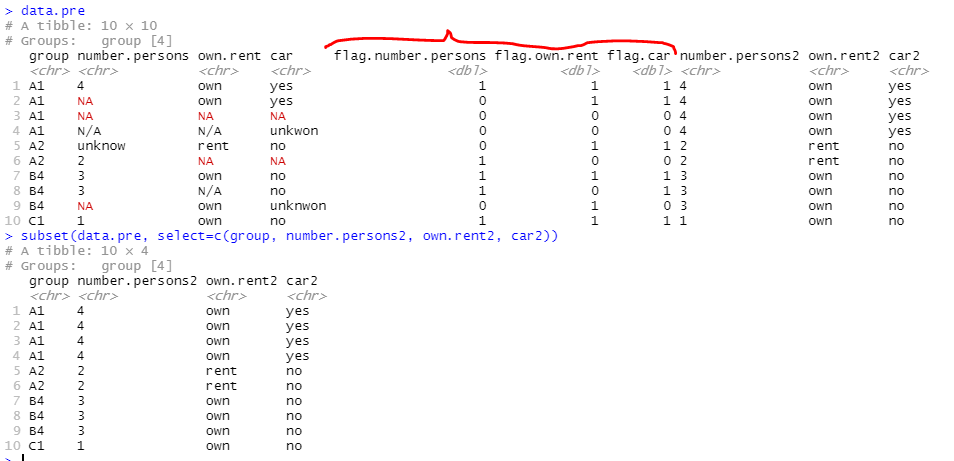
My solution so far is kind of tedious since I am making new variables as flags to tag the "valid value" according conditions stablished and then mutate replacing with the valid values ( I am actually making another variables just to test code), but first, making so many variables is slow and a mess, and second I have like 500 variables then making flags for each one doesn't make any sense. Is there a faster/elegant way to do this? Maybe a function that receive the variables I want to clean and the list of no-valid values?
CodePudding user response:
Here's a shorthand approach where I specify the column(s) that should be numbers, and another with text where I specify the allowable vocabulary. Any other answers are made NA and then I fill within groups.
You could make this as specific as to which columns have what vocabulary as you like. I combined the own/rent and yes/no answer into one allowable vocabulary, but those could be separate.
library(tidyverse)
data %>%
mutate(across(number.persons, ~parse_number(.x)),
across(own.rent:car, ~if_else(.x %in% c("own", "rent", "yes", "no"),
.x, NA))) %>%
group_by(group) %>%
fill(-group, .direction = "downup") %>%
ungroup()
group number.persons own.rent car
<chr> <dbl> <chr> <chr>
1 A1 4 own yes
2 A1 4 own yes
3 A1 4 own yes
4 A1 4 own yes
5 A2 2 rent no
6 A2 2 rent no
7 B4 3 own no
8 B4 3 own no
9 B4 3 own no
10 C1 1 own no
CodePudding user response:
If the several words beginning with "unk" represent unknown", then there are several typos and the mutate below becomes a bit messy. But nothing to despair.
suppressPackageStartupMessages({
library(dplyr)
library(zoo)
})
data <- data.frame(group = c("A1", "A1", "A1", "A1", "A2", "A2", "B4", "B4", "B4", "C1"),
number.persons = c("4",NA,NA, "N/A", "unknow", "2", "3", "3", NA,"1"),
own.rent = c("own", "own", NA, "N/A", "rent", NA, "own", "N/A", "own", "own"),
car = c("yes", "yes", NA, "unkwon", "no", NA, "no", "no", "unknwon", "no"))
data %>%
group_by(group) %>%
mutate(across(everything(), ~ if_else(.x == "N/A", NA_character_, .x)),
across(everything(), ~ if_else(grepl("^unk", .x), NA_character_, .x))) %>%
mutate(across(everything(), na.locf))
#> # A tibble: 10 × 4
#> # Groups: group [4]
#> group number.persons own.rent car
#> <chr> <chr> <chr> <chr>
#> 1 A1 4 own yes
#> 2 A1 4 own yes
#> 3 A1 4 own yes
#> 4 A1 4 own yes
#> 5 A2 2 rent no
#> 6 A2 2 rent no
#> 7 B4 3 own no
#> 8 B4 3 own no
#> 9 B4 3 own no
#> 10 C1 1 own no
Created on 2022-09-09 by the reprex package (v2.0.1)